Hugging Face AutoTrain
2 minute read
Hugging Face AutoTrain は、自然言語処理 (NLP) タスク、コンピュータビジョン (CV) タスク、スピーチ タスク、さらには表形式のタスクのための最先端モデルをトレーニングするノーコードツールです。
Weights & Biases は Hugging Face AutoTrain に直接インテグレーションされています。実験管理と設定管理を提供します。実験には CLI コマンド内の単一パラメータを使用するだけで簡単です。
必要条件をインストールする
autotrain-advanced と wandb をインストールします。
pip install --upgrade autotrain-advanced wandb
!pip install --upgrade autotrain-advanced wandb
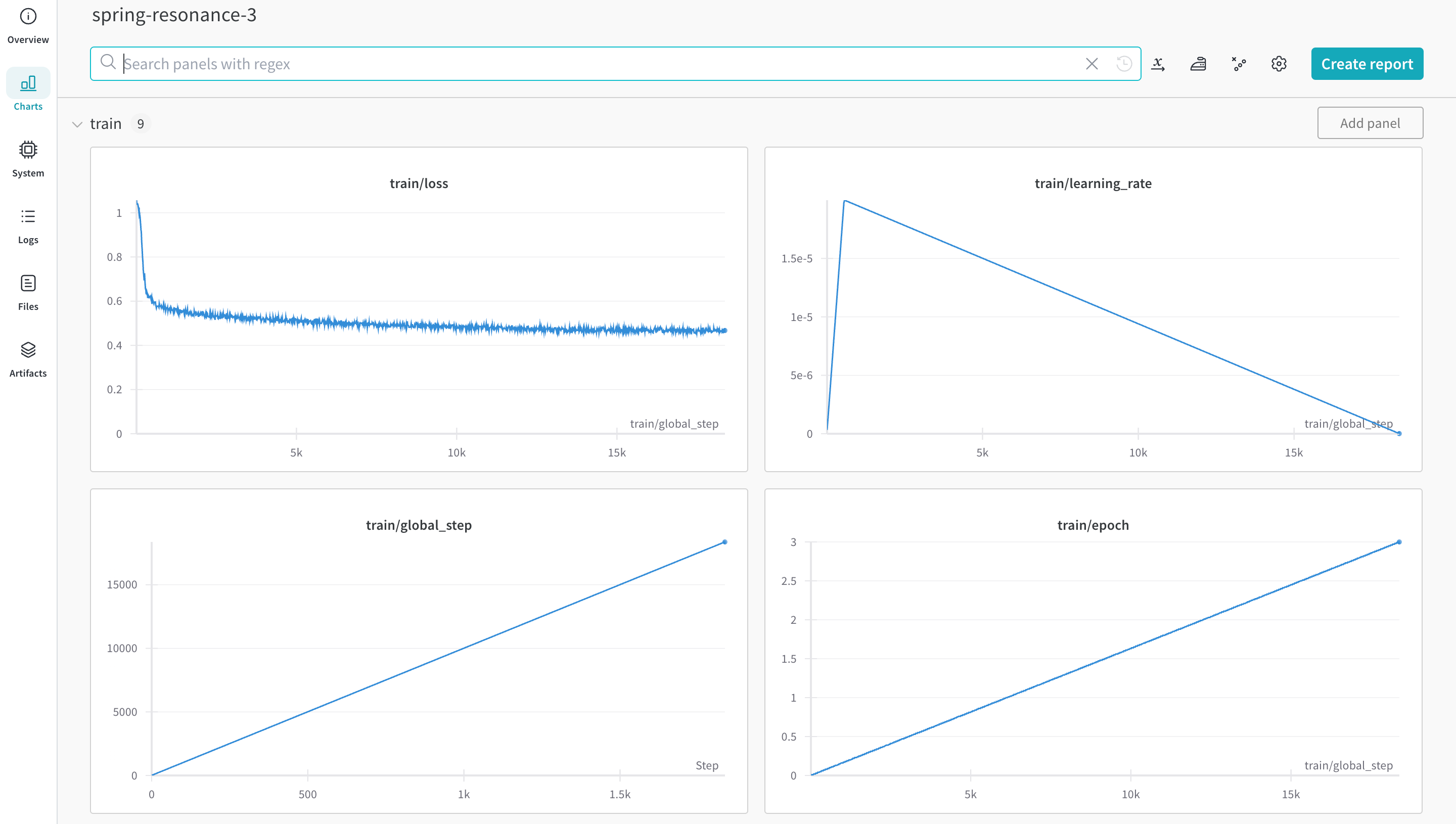
これらの変更を示すために、このページでは数学データセット上での LLM の微調整を行い、GSM8k Benchmarks での pass@1 での最先端の結果を達成します。
データセットを準備する
Hugging Face AutoTrain は、独自の CSV データセットが適切に動作するために特定の形式を持つことを期待しています。
-
トレーニングファイルには、トレーニングで使用される
textカラムが含まれている必要があります。最良の結果を得るために、textカラムのデータは### Human: Question?### Assistant: Answer.形式に準拠している必要があります。timdettmers/openassistant-guanacoに優れた例を確認してください。しかし、MetaMathQA データセット には、
query、response、typeのカラムが含まれています。まず、このデータセットを前処理します。typeカラムを削除し、queryとresponseカラムの内容を### Human: Query?### Assistant: Response.形式で新しいtextカラムに結合します。トレーニングは、結果のデータセット、rishiraj/guanaco-style-metamathを使用します。
autotrain を使用したトレーニング
コマンドラインまたはノートブックから autotrain の高度な機能を使用してトレーニングを開始できます。--log 引数を使用するか、--log wandb を使用して、W&B run に結果をログします。
autotrain llm \
--train \
--model HuggingFaceH4/zephyr-7b-alpha \
--project-name zephyr-math \
--log wandb \
--data-path data/ \
--text-column text \
--lr 2e-5 \
--batch-size 4 \
--epochs 3 \
--block-size 1024 \
--warmup-ratio 0.03 \
--lora-r 16 \
--lora-alpha 32 \
--lora-dropout 0.05 \
--weight-decay 0.0 \
--gradient-accumulation 4 \
--logging_steps 10 \
--fp16 \
--use-peft \
--use-int4 \
--merge-adapter \
--push-to-hub \
--token <huggingface-token> \
--repo-id <huggingface-repository-address>
# ハイパーパラメーターを設定する
learning_rate = 2e-5
num_epochs = 3
batch_size = 4
block_size = 1024
trainer = "sft"
warmup_ratio = 0.03
weight_decay = 0.
gradient_accumulation = 4
lora_r = 16
lora_alpha = 32
lora_dropout = 0.05
logging_steps = 10
# トレーニングを実行する
!autotrain llm \
--train \
--model "HuggingFaceH4/zephyr-7b-alpha" \
--project-name "zephyr-math" \
--log "wandb" \
--data-path data/ \
--text-column text \
--lr str(learning_rate) \
--batch-size str(batch_size) \
--epochs str(num_epochs) \
--block-size str(block_size) \
--warmup-ratio str(warmup_ratio) \
--lora-r str(lora_r) \
--lora-alpha str(lora_alpha) \
--lora-dropout str(lora_dropout) \
--weight-decay str(weight_decay) \
--gradient-accumulation str(gradient_accumulation) \
--logging-steps str(logging_steps) \
--fp16 \
--use-peft \
--use-int4 \
--merge-adapter \
--push-to-hub \
--token str(hf_token) \
--repo-id "rishiraj/zephyr-math"
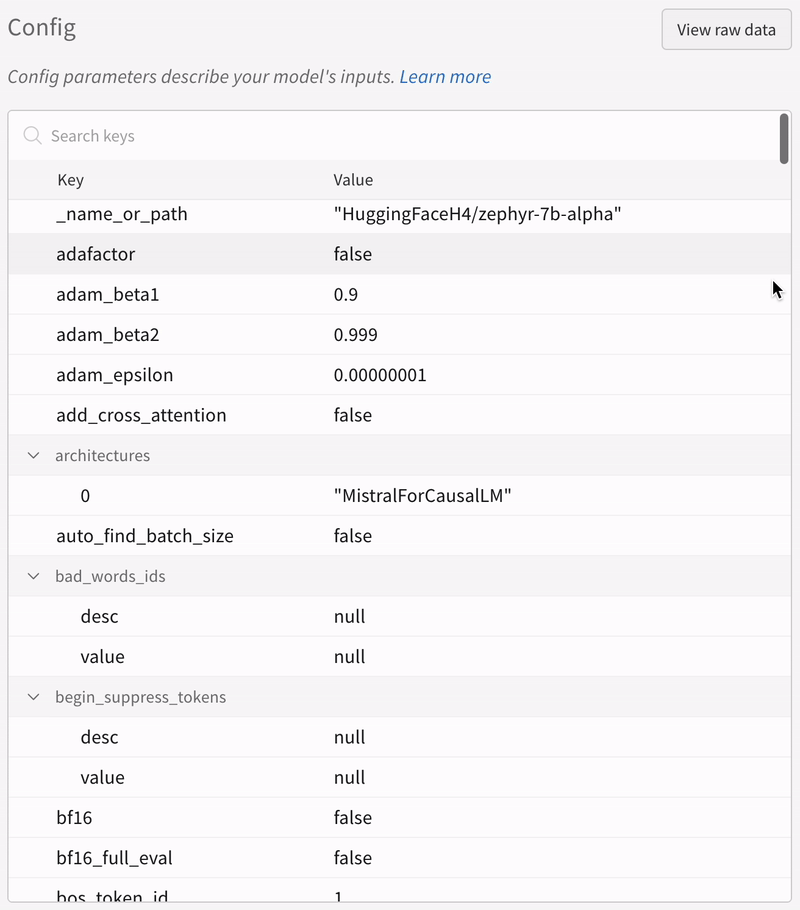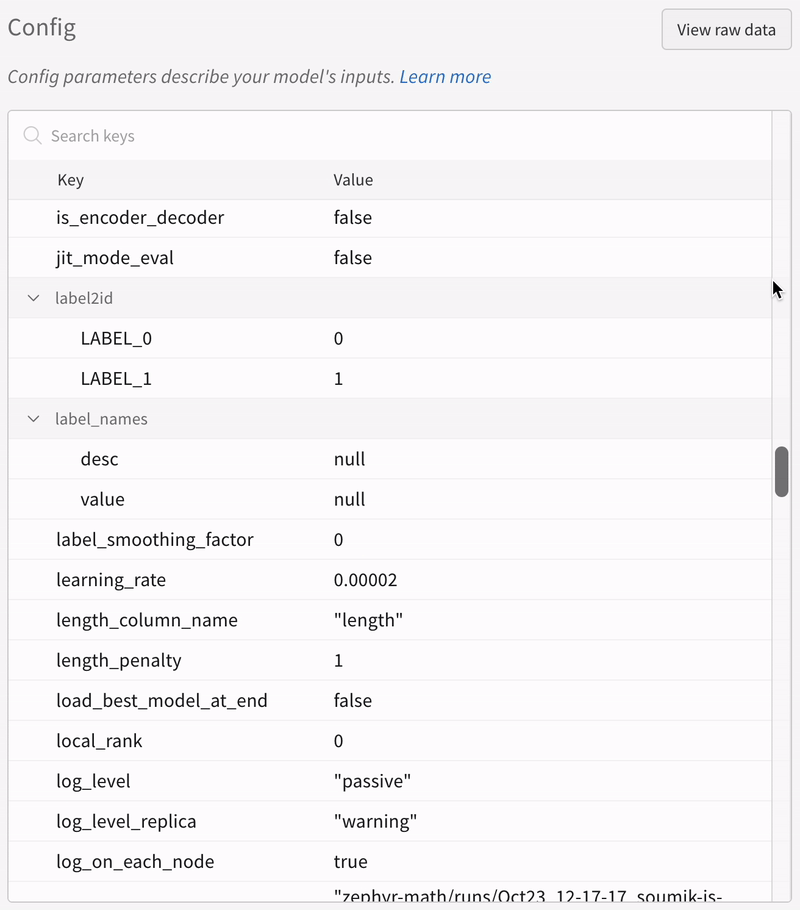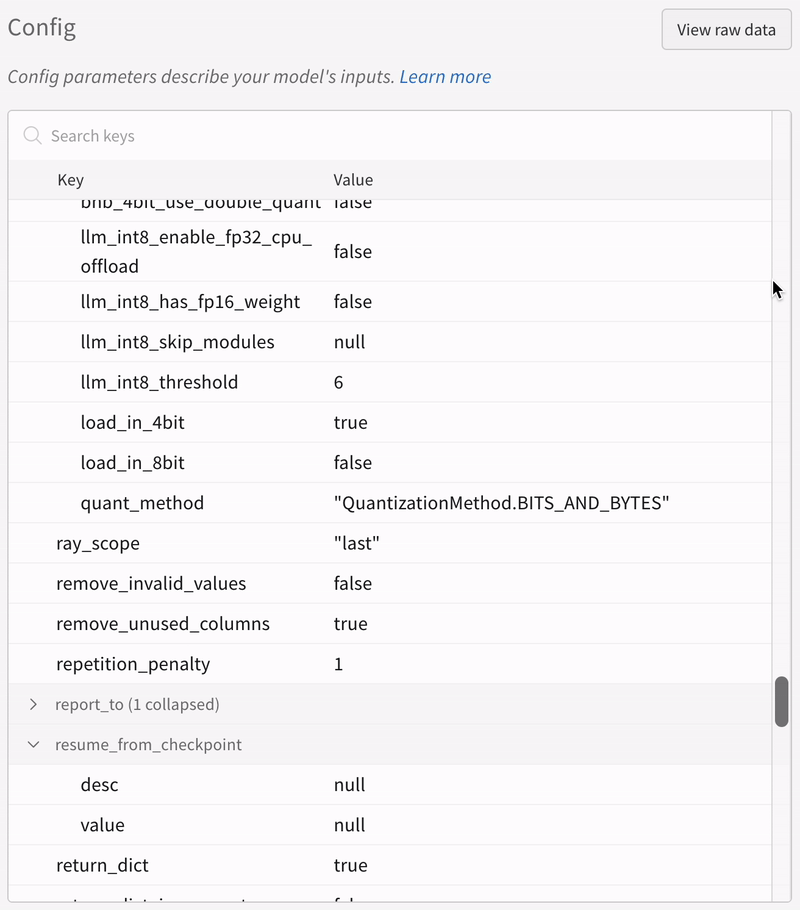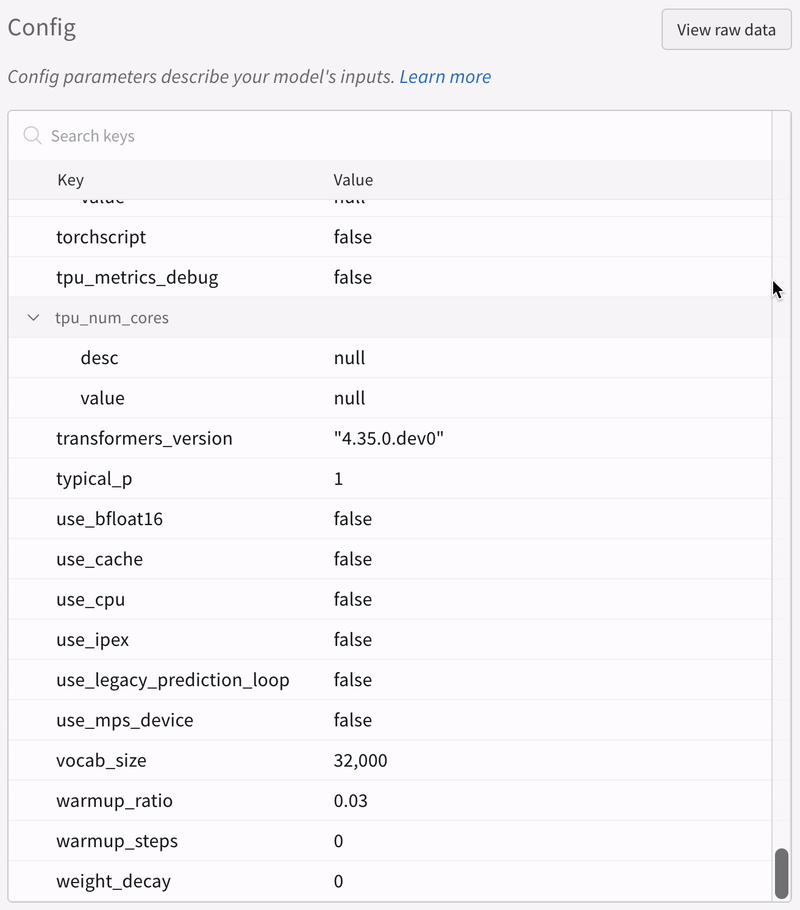
追加のリソース
フィードバック
このページは役に立ちましたか?
Glad to hear it! If you have more to say, please let us know.
Sorry to hear that. Please tell us how we can improve.