ログ オブジェクト と メディア
メトリクス、ビデオ、カスタムプロットなどを追跡する
W&B Python SDK を使用して、メトリクス、メディア、またはカスタムオブジェクトの辞書をステップにログします。W&B は各ステップごとにキーと値のペアを収集し、wandb.log() でデータをログするたびにそれらを統一された辞書に格納します。スクリプトからログされたデータは、wandb と呼ばれるディレクトリにローカルに保存され、その後 W&B クラウドまたは プライベートサーバー に同期されます。
キーと値のペアは、各ステップに同じ値を渡した場合にのみ統一された辞書に保存されます。step に異なる値をログした場合、W&B はすべての収集されたキーと値をメモリに書き込みます。
デフォルトでは、wandb.log を呼び出すたびに新しい step になります。W&B は、チャートやパネルを作成する際にステップをデフォルトの x 軸として使用します。カスタムの x 軸を作成して使用するか、カスタムの要約メトリックをキャプチャすることも選択できます。詳細は、ログの軸をカスタマイズする を参照してください。
wandb.log() を使用して、各 step の連続する値をログします: 0, 1, 2, といった具合です。特定の履歴ステップに書き込むことは不可能です。W&B は「現在」と「次」のステップにのみ書き込みます。
自動でログされるデータ
W&B は、W&B Experiment 中に次の情報を自動でログします:
システムメトリクス : CPU と GPU の使用率、ネットワークなど。これらは run ページ のシステムタブに表示されます。GPU に関しては、nvidia-smiコマンドライン : stdout と stderr が取得され、run ページ のログタブに表示されます。
アカウントの Settings ページ でコードの保存 をオンにして、以下をログします:
Git コミット : 最新の git コミットを取得し、run ページの overview タブに表示されます。コミットされていない変更がある場合は diff.patch ファイルも表示されます。依存関係 : requirements.txt ファイルがアップロードされ、run ページのファイルタブに表示されます。run 用に wandb ディレクトリに保存したファイルも含まれます。
特定の W&B API 呼び出しでログされるデータ
W&B を使用することで、ログしたいものを正確に決定できます。次に、よくログされるオブジェクトのリストを示します:
Datasets : 画像や他のデータセットサンプルを W&B にストリームするためには、特にログする必要があります。Plots : グラフを追跡するために wandb.plot を wandb.log と一緒に使用します。詳細はログでのグラフ を参照してください。Tables : wandb.Table を使用してデータをログし、W&B でビジュアライズおよびクエリを行います。詳細はログでのテーブル を参照してください。PyTorch 勾配 : モデルの重みの勾配を UI にヒストグラムとして表示するために wandb.watch(model) を追加します。設定情報 : ハイパーパラメーター、データセットへのリンク、使用しているアーキテクチャーの名前などを設定パラメーターとしてログします。このように渡します:wandb.init(config=your_config_dictionary)。詳細はPyTorch インテグレーション ページをご覧ください。メトリクス : wandb.log を使用してモデルのメトリクスを表示します。トレーニングループ内で精度や損失のようなメトリクスをログすると、UI にライブ更新グラフが表示されます。
一般的なワークフロー
最高の精度を比較する : Runs 間でメトリクスの最高値を比較するには、そのメトリクスの要約値を設定します。デフォルトでは、各キーの最後にログした値が要約に設定されます。これは UI のテーブルで、要約メトリクスに基づいて run を並べ替えたりフィルタリングしたりするのに便利です。best の精度に基づいてテーブルまたは棒グラフで run を比較するのに役立ちます。例:wandb.run.summary["best_accuracy"] = best_accuracy複数のメトリクスを1つのチャートで表示 : wandb.log の同じ呼び出し内で複数のメトリクスをログすると、例えばこうなります: wandb.log({"acc": 0.9, "loss": 0.1})。UI ではどちらもプロットすることができます。x 軸をカスタマイズする : 同じログ呼び出しにカスタム x 軸を追加して、W&B ダッシュボードで別の軸に対してメトリクスを視覚化します。例:wandb.log({'acc': 0.9, 'epoch': 3, 'batch': 117})。特定のメトリクスに対するデフォルトの x 軸を設定するには、Run.define_metric() を使用してください。リッチメディアとチャートをログする : wandb.log は、画像やビデオのようなメディア からtables やcharts に至るまで、多様なデータタイプのログをサポートしています。
ベストプラクティスとヒント
Experiments やログのためのベストプラクティスとヒントについては、Best Practices: Experiments and Logging を参照してください。
1 - メディアとオブジェクトをログする
3D ポイント クラウドや分子から HTML、ヒストグラムまで、豊富なメディアをログする
私たちは画像、ビデオ、音声などをサポートしています。リッチメディアをログして、結果を探索し、Run、Models、Datasetsを視覚的に比較しましょう。例やハウツーガイドは以下をご覧ください。
メディアタイプの参考ドキュメントをお探しですか?この
ページ が必要です。
前提条件
W&B SDKを使用してメディアオブジェクトをログするためには、追加の依存関係をインストールする必要があるかもしれません。以下のコマンドを実行してこれらの依存関係をインストールできます:
画像
画像をログして、入力、出力、フィルター重み、活性化状態などを追跡しましょう。
画像はNumPy配列、PIL画像、またはファイルシステムから直接ログできます。
ステップごとに画像をログするたびに、UIに表示するために保存されます。画像パネルを拡大し、ステップスライダーを使用して異なるステップの画像を確認します。これにより、トレーニング中にモデルの出力がどのように変化するかを比較しやすくなります。
トレーニング中のログのボトルネックを防ぎ、結果を表示する際の画像読み込みのボトルネックを防ぐために、1ステップあたり50枚以下の画像をログすることをお勧めします。
配列を画像としてログする
PIL Imagesをログする
ファイルから画像をログする
配列を手動で画像として構築する際に、make_grid from torchvision
配列はPillow を使用してpngに変換されます。
images = wandb. Image(image_array, caption= "Top: Output, Bottom: Input" )
wandb. log({"examples" : images})
最後の次元が1の場合はグレースケール、3の場合はRGB、4の場合はRGBAと仮定します。配列が浮動小数点数を含む場合、それらを0から255の整数に変換します。異なる方法で画像を正規化したい場合は、mode"Logging PIL Images"タブで説明されているように、単にPIL.Image
配列から画像への変換を完全に制御するために、PIL.Image
images = [PIL. Image. fromarray(image) for image in image_array]
wandb. log({"examples" : [wandb. Image(image) for image in images]})
さらに制御したい場合は、任意の方法で画像を作成し、ディスクに保存し、ファイルパスを提供します。
im = PIL. fromarray(... )
rgb_im = im. convert("RGB" )
rgb_im. save("myimage.jpg" )
wandb. log({"example" : wandb. Image("myimage.jpg" )})
画像オーバーレイ
セマンティックセグメンテーションマスクをログし、W&B UIを通じて(不透明度の変更、時間経過による変化の確認など)それらと対話します。
オーバーレイをログするには、wandb.Imageのmasksキーワード引数に以下のキーと値を持つ辞書を提供する必要があります:
画像マスクを表す2つのキーのうちの1つ:
"mask_data":各ピクセルの整数クラスラベルを含む2D NumPy配列"path":(文字列)保存された画像マスクファイルへのパス
"class_labels":(オプション)画像マスク内の整数クラスラベルを可読クラス名にマッピングする辞書
複数のマスクをログするには、以下のコードスニペットのように、複数のキーを含むマスク辞書をログします。
ライブ例を参照してください
サンプルコード
mask_data = np. array([[1 , 2 , 2 , ... , 2 , 2 , 1 ], ... ])
class_labels = {1 : "tree" , 2 : "car" , 3 : "road" }
mask_img = wandb. Image(
image,
masks= {
"predictions" : {"mask_data" : mask_data, "class_labels" : class_labels},
"ground_truth" : {
# ...
},
# ...
},
)
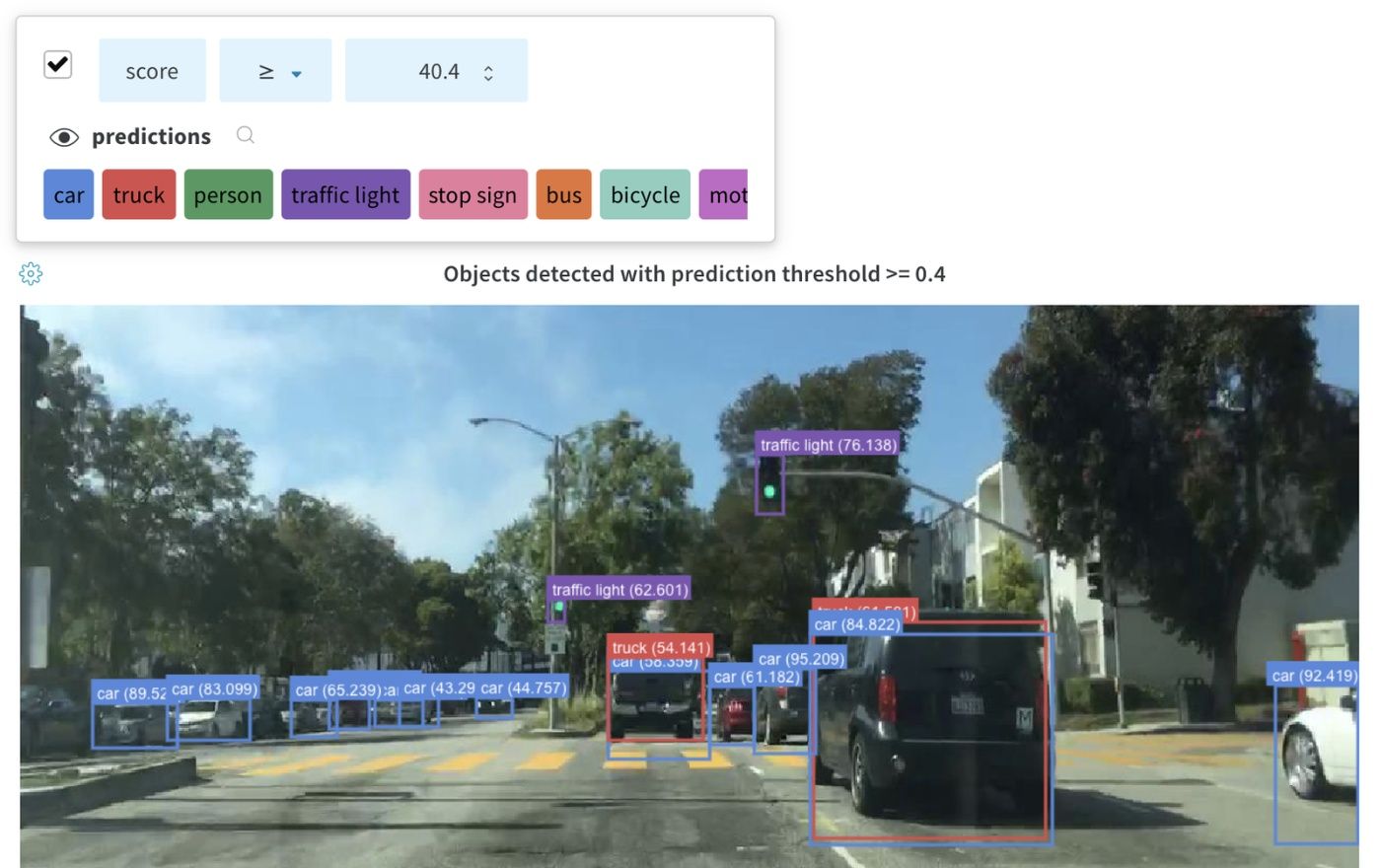
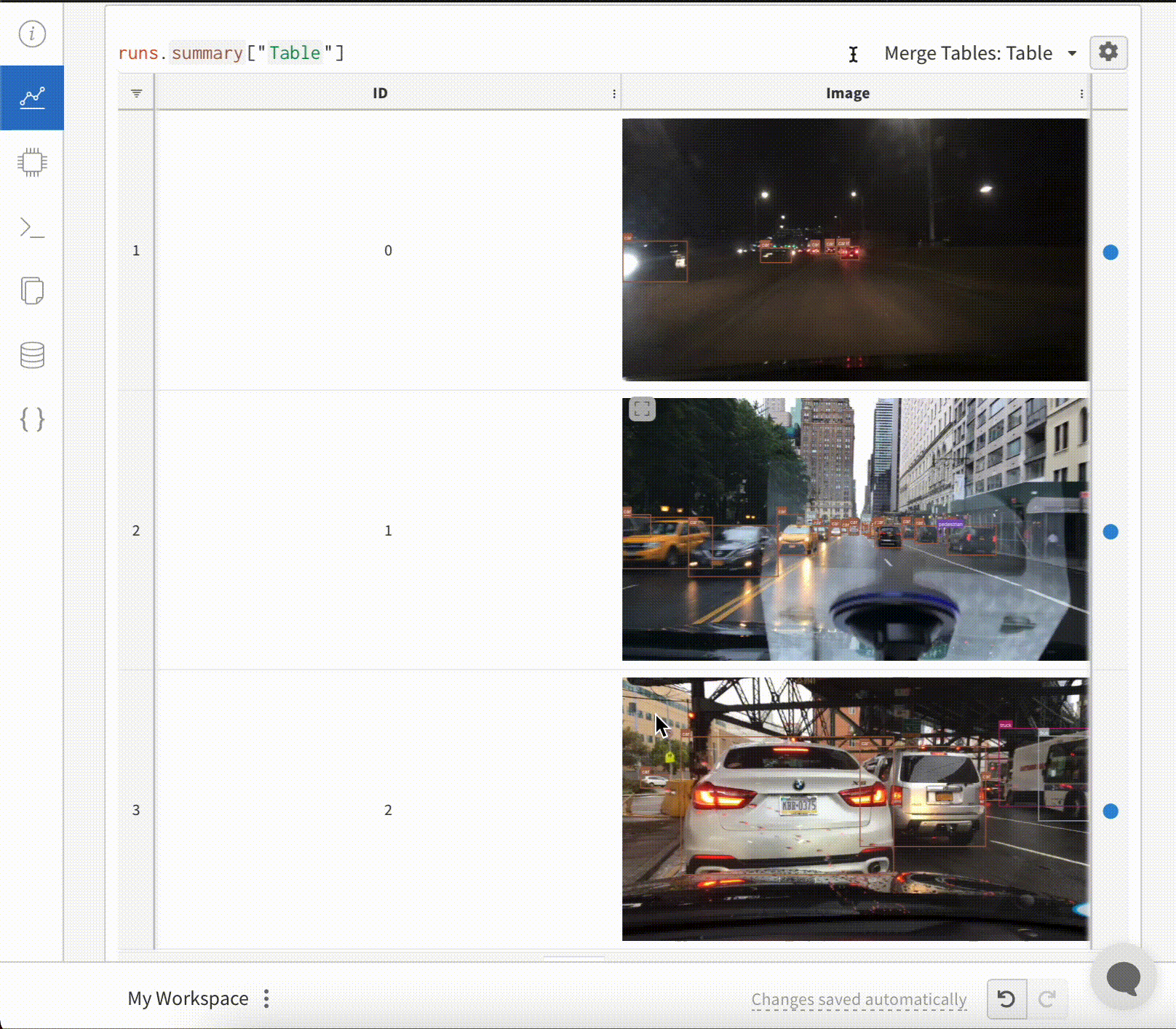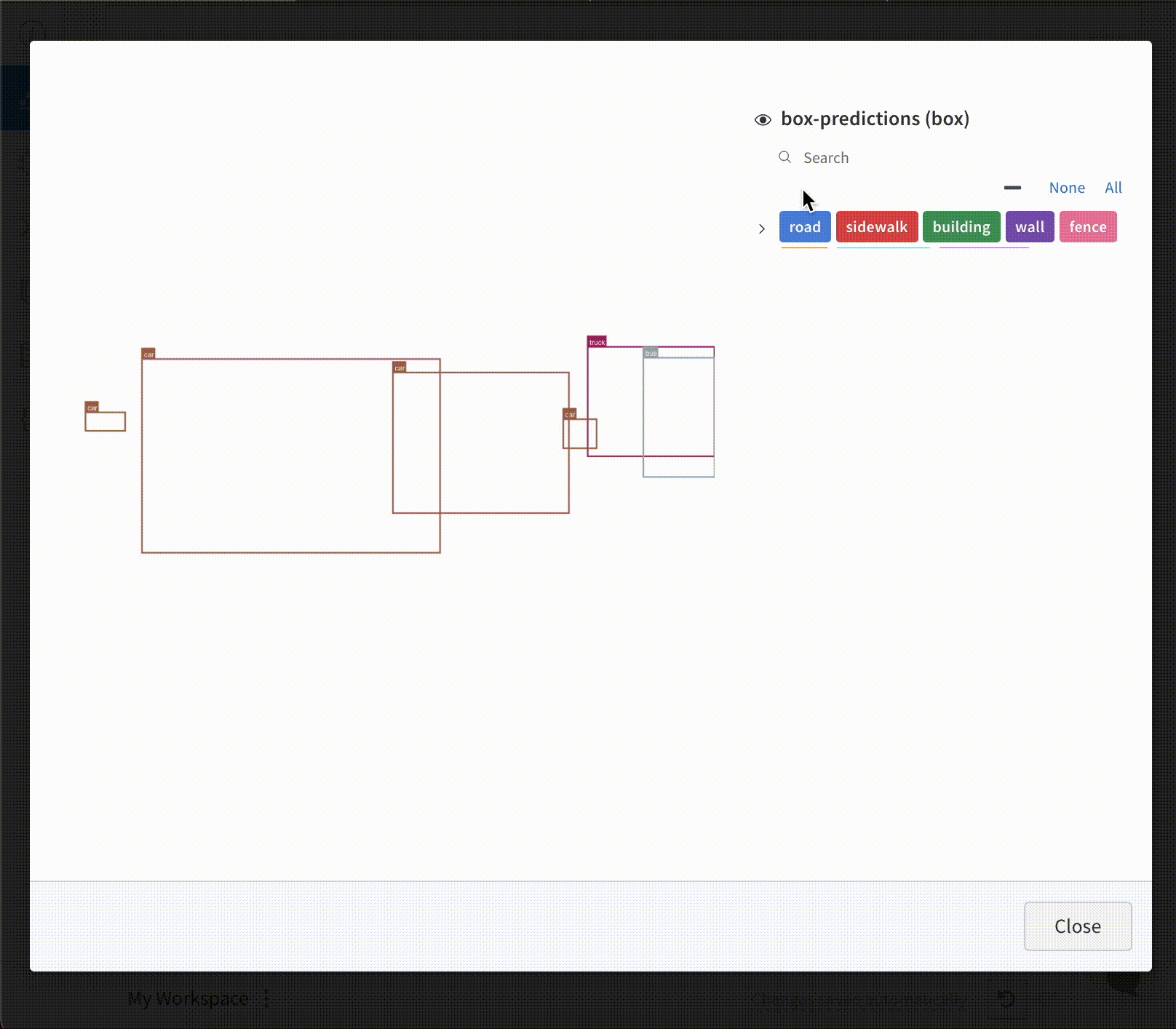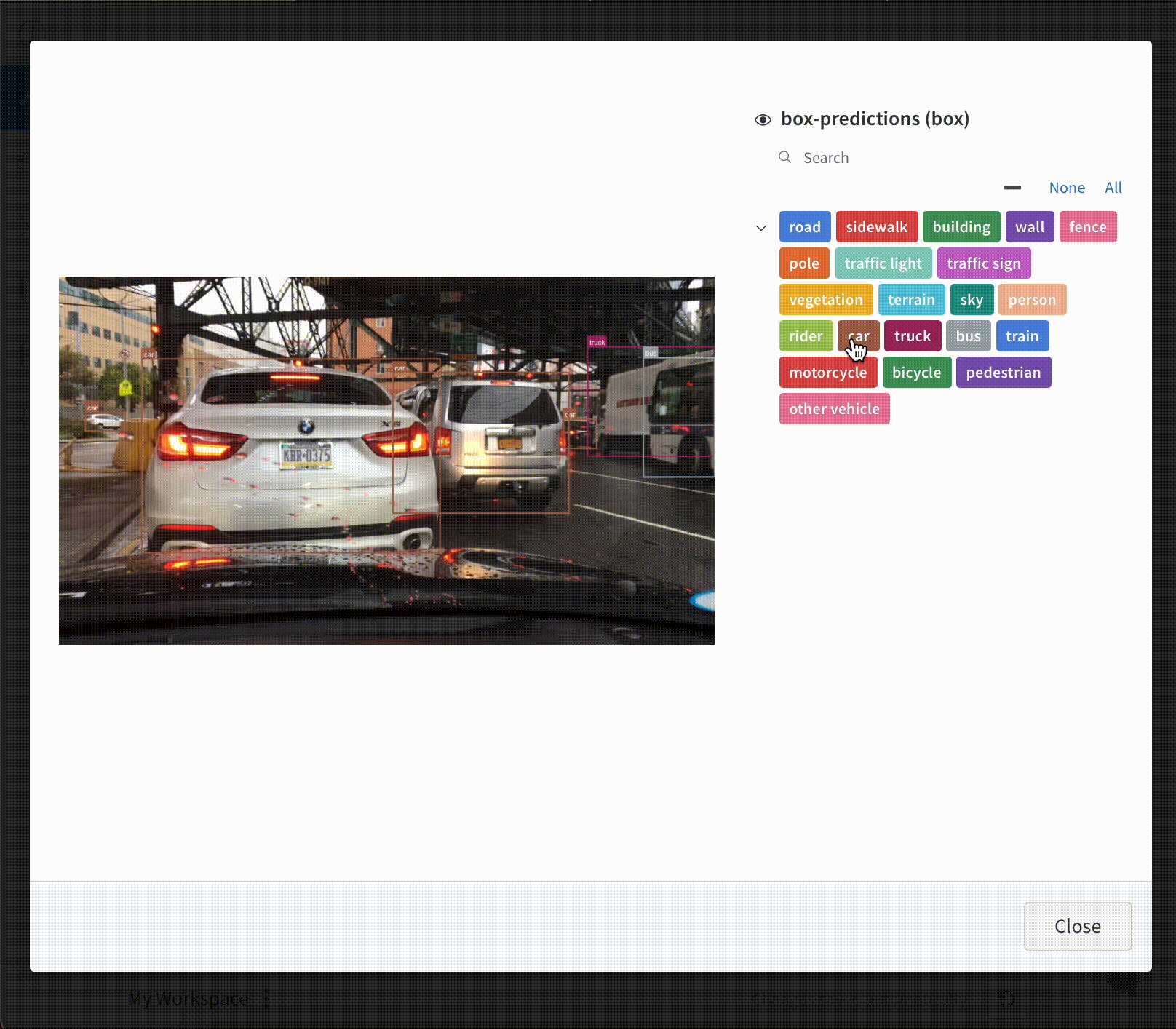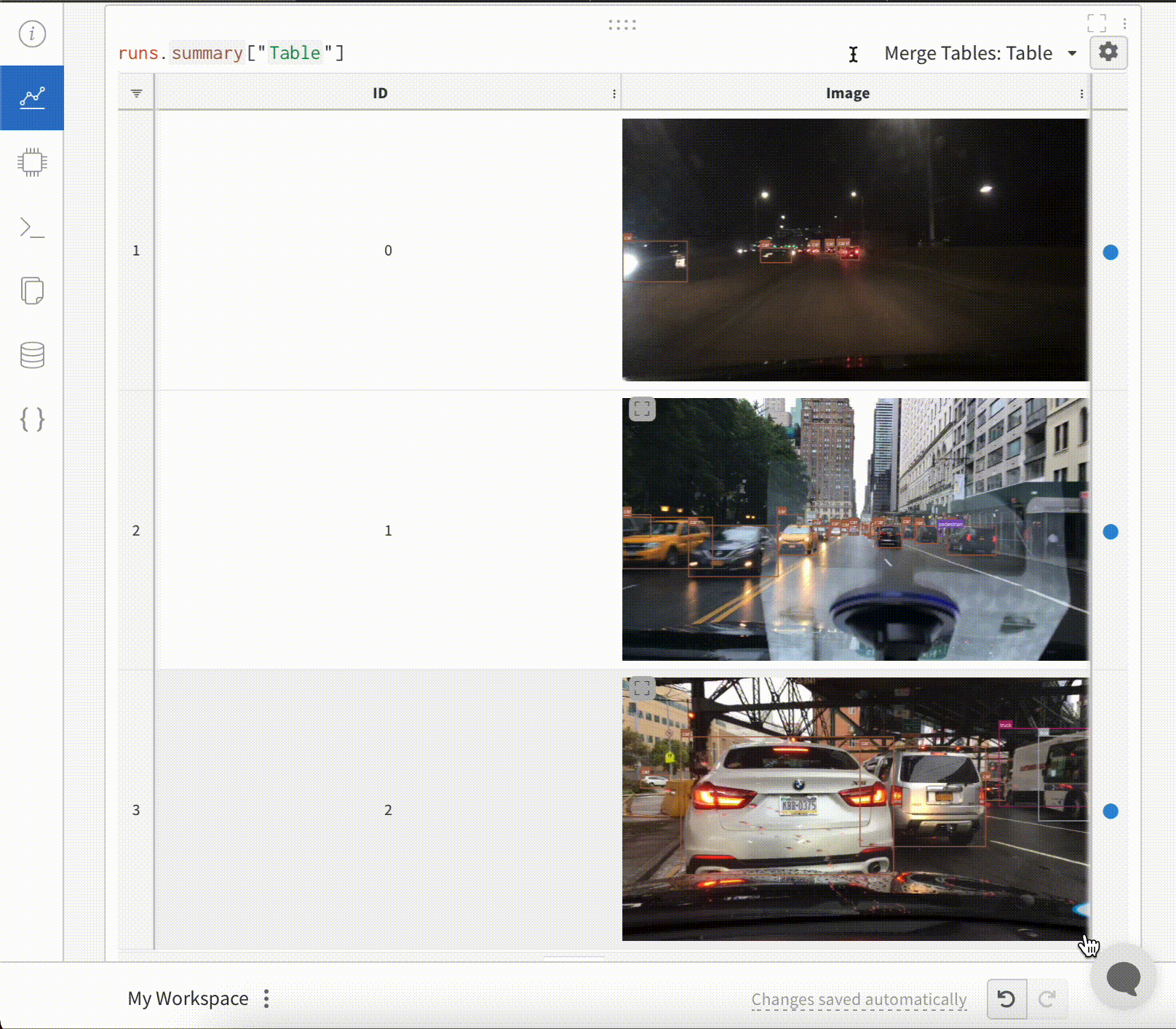
画像にバウンディングボックスをログし、UIで異なるセットのボックスを動的に可視化するためにフィルターや切り替えを使用します。
ライブ例を参照してください
バウンディングボックスをログするには、wandb.Imageのboxesキーワード引数に以下のキーと値を持つ辞書を提供する必要があります:
box_data:各ボックス用の辞書リスト。ボックス辞書形式は以下に説明します。
position:ボックスの位置とサイズを表す辞書で、以下で説明する2つの形式のいずれか。すべてのボックスが同じ形式を使用する必要はありません。
オプション 1: {"minX", "maxX", "minY", "maxY"}。各ボックスの次元の上下限を定義する座標セットを提供します。オプション 2: {"middle", "width", "height"}。middle座標を[x,y]として、widthとheightをスカラーとして指定します。
class_id:ボックスのクラス識別を表す整数。以下のclass_labelsキーを参照。scores:スコアの文字列ラベルと数値の辞書。UIでボックスをフィルタリングするために使用できます。domain:ボックス座標の単位/形式を指定してください。この値を"pixel"に設定 してください。ボックス座標が画像の次元内の整数のようにピクセル空間で表されている場合、デフォルトで、domainは画像の割合/百分率として表され、0から1までの浮動小数点数として解釈されます。box_caption:(オプション)このボックス上に表示されるラベルテキストとしての文字列
class_labels:(オプション)class_idを文字列にマッピングする辞書。デフォルトではclass_0、class_1などのクラスラベルを生成します。
この例をチェックしてください:
class_id_to_label = {
1 : "car" ,
2 : "road" ,
3 : "building" ,
# ...
}
img = wandb. Image(
image,
boxes= {
"predictions" : {
"box_data" : [
{
# デフォルトの相対/小数領域で表現された1つのボックス
"position" : {"minX" : 0.1 , "maxX" : 0.2 , "minY" : 0.3 , "maxY" : 0.4 },
"class_id" : 2 ,
"box_caption" : class_id_to_label[2 ],
"scores" : {"acc" : 0.1 , "loss" : 1.2 },
# ピクセル領域で表現された別のボックス
# (説明目的のみ、すべてのボックスは同じ領域/形式である可能性が高い)
"position" : {"middle" : [150 , 20 ], "width" : 68 , "height" : 112 },
"domain" : "pixel" ,
"class_id" : 3 ,
"box_caption" : "a building" ,
"scores" : {"acc" : 0.5 , "loss" : 0.7 },
# ...
# 必要に応じて多くのボックスをログします
}
],
"class_labels" : class_id_to_label,
},
# 意味のあるボックスのグループごとに一意のキーネームでログします
"ground_truth" : {
# ...
},
},
)
wandb. log({"driving_scene" : img})
テーブル内の画像オーバーレイ
テーブル内でセグメンテーションマスクをログするには、テーブルの各行に対してwandb.Imageオブジェクトを提供する必要があります。
以下のコードスニペットに例があります:
table = wandb. Table(columns= ["ID" , "Image" ])
for id, img, label in zip(ids, images, labels):
mask_img = wandb. Image(
img,
masks= {
"prediction" : {"mask_data" : label, "class_labels" : class_labels}
# ...
},
)
table. add_data(id, img)
wandb. log({"Table" : table})
テーブル内でバウンディングボックス付き画像をログするには、テーブルの各行にwandb.Imageオブジェクトを提供する必要があります。
以下のコードスニペットに例があります:
table = wandb. Table(columns= ["ID" , "Image" ])
for id, img, boxes in zip(ids, images, boxes_set):
box_img = wandb. Image(
img,
boxes= {
"prediction" : {
"box_data" : [
{
"position" : {
"minX" : box["minX" ],
"minY" : box["minY" ],
"maxX" : box["maxX" ],
"maxY" : box["maxY" ],
},
"class_id" : box["class_id" ],
"box_caption" : box["caption" ],
"domain" : "pixel" ,
}
for box in boxes
],
"class_labels" : class_labels,
}
},
)
ヒストグラム
基本ヒストグラムログ
柔軟なヒストグラムログ
Summary内のヒストグラム
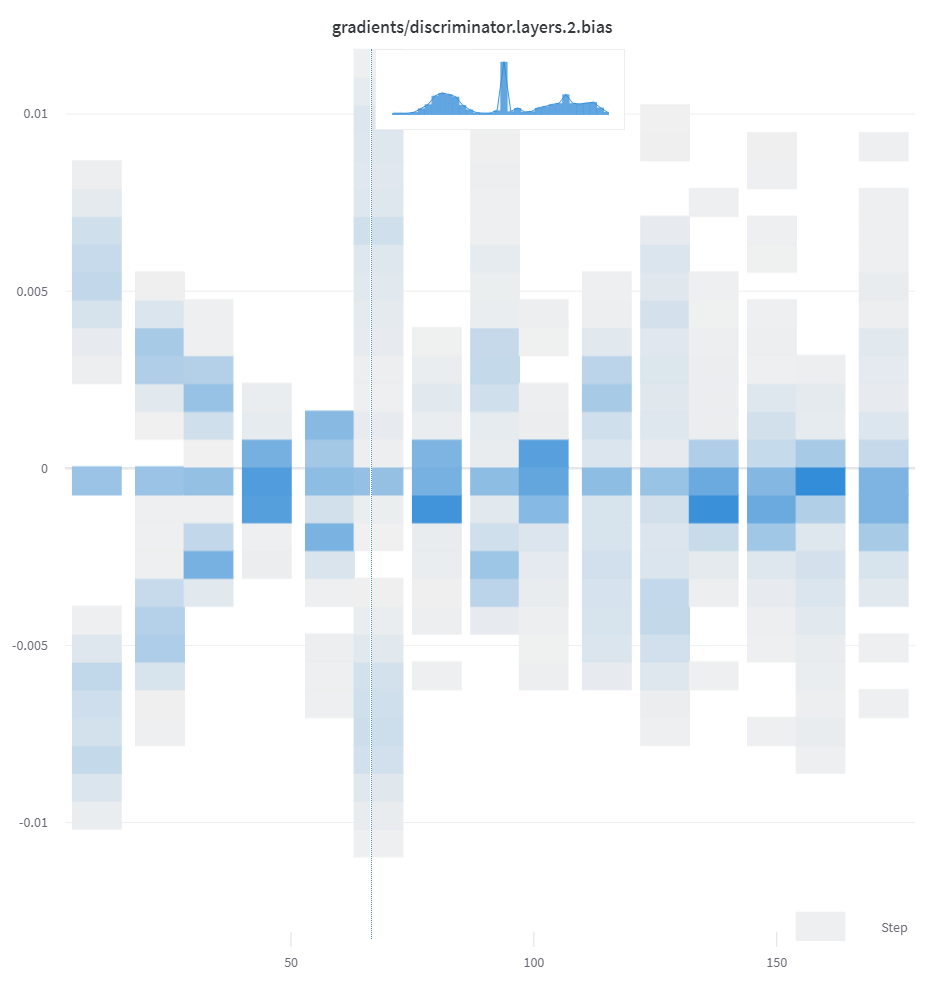
リスト、配列、テンソルなどの数字のシーケンスが最初の引数として提供されると、自動的にnp.histogramを呼んでヒストグラムを構築します。すべての配列/テンソルはフラット化されます。num_binsキーワード引数を使用して64ビンのデフォルト設定を上書きできます。最大サポートビン数は512です。
UIでは、トレーニングステップがx軸に、メトリック値がy軸に、色で表現されたカウントでヒストグラムがプロットされ、トレーニング中にログされたヒストグラムを比較しやすくしています。詳細については、このパネルの"Summary内のヒストグラム"タブを参照してください。
wandb. log({"gradients" : wandb. Histogram(grads)})
もっと制御したい場合は、np.histogramを呼び出し、その返されたタプルをnp_histogramキーワード引数に渡します。
np_hist_grads = np. histogram(grads, density= True , range= (0.0 , 1.0 ))
wandb. log({"gradients" : wandb. Histogram(np_hist_grads)})
wandb. run. summary. update( # Summaryにのみある場合、Overviewタブにのみ表示されます
{"final_logits" : wandb. Histogram(logits)}
)
ファイルを形式 'obj', 'gltf', 'glb', 'babylon', 'stl', 'pts.json' でログすれば、runが終了した際にUIでそれらをレンダリングします。
wandb. log(
{
"generated_samples" : [
wandb. Object3D(open("sample.obj" )),
wandb. Object3D(open("sample.gltf" )),
wandb. Object3D(open("sample.glb" )),
]
}
)
ライブ例を見る
Summary内にあるヒストグラムは、Run Page のOverviewタブに表示されます。履歴にある場合、Chartsタブで時間経過によるビンのヒートマップをプロットします。
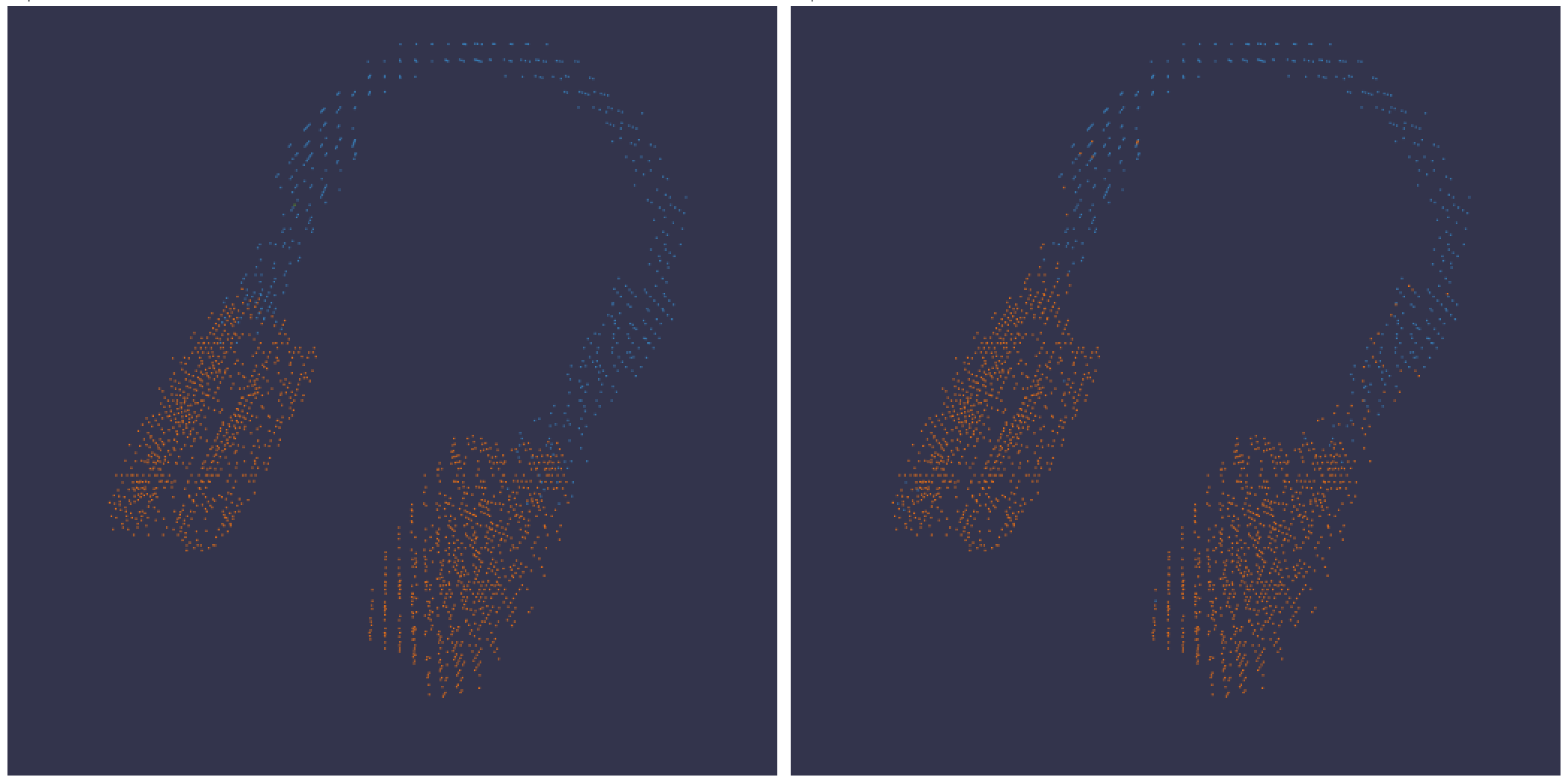
3D可視化
3Dポイントクラウドとバウンディングボックスを持つLidarシーンをログします。レンダリングするポイントの座標と色を含むNumPy配列を渡します。
point_cloud = np. array([[0 , 0 , 0 , COLOR]])
wandb. log({"point_cloud" : wandb. Object3D(point_cloud)})
:::info
W&B UIはデータを30万ポイントに制限します。
:::
NumPy配列フォーマット
色のスキームに柔軟性を持たせるために、3つの異なるデータ形式のNumPy配列がサポートされています。
[[x, y, z], ...] nx3[[x, y, z, c], ...] nx4, cは範囲[1, 14]内のカテゴリ (セグメンテーションに便利)[[x, y, z, r, g, b], ...] nx6 | r,g,b は赤、緑、青のカラー チャネルに対して範囲[0,255]の値
Pythonオブジェクト
このスキーマを使用して、Pythonオブジェクトを定義し、以下に示すように the from_point_cloud method に渡すことができます。
pointsは、単純なポイントクラウドレンダラーで上記に示されたのと同じフォーマットを使用してレンダリングするポイントの座標と色を含むNumPy配列です 。boxesは3つの属性を持つPython辞書のNumPy配列です:
corners - 8つのコーナーのリストlabel - ボックスにレンダリングされるラベルを表す文字列 (オプション)color - ボックスの色を表すrgb値score - バウンディングボックスに表示される数値で、表示するバウンディングボックスのフィルタリングに使用できます(例:score > 0.75のバウンディングボックスのみを表示する)。(オプション)
typeはレンダリングされるシーンタイプを表す文字列です。現在サポートされている値はlidar/betaのみです。
point_list = [
[
2566.571924017235 , # x
746.7817289698219 , # y
- 15.269245470863748 ,# z
76.5 , # red
127.5 , # green
89.46617199365393 # blue
],
[ 2566.592983606823 , 746.6791987335685 , - 15.275803826279521 , 76.5 , 127.5 , 89.45471117247024 ],
[ 2566.616361739416 , 746.4903185513501 , - 15.28628929674075 , 76.5 , 127.5 , 89.41336375503832 ],
[ 2561.706014951675 , 744.5349468458361 , - 14.877496818222781 , 76.5 , 127.5 , 82.21868245418283 ],
[ 2561.5281847916694 , 744.2546118233013 , - 14.867862032341005 , 76.5 , 127.5 , 81.87824684536432 ],
[ 2561.3693562897465 , 744.1804761656741 , - 14.854129178142523 , 76.5 , 127.5 , 81.64137897587152 ],
[ 2561.6093071504515 , 744.0287526628543 , - 14.882135189841177 , 76.5 , 127.5 , 81.89871499537098 ],
# ... and so on
]
run. log({"my_first_point_cloud" : wandb. Object3D. from_point_cloud(
points = point_list,
boxes = [{
"corners" : [
[ 2601.2765123137915 , 767.5669506323393 , - 17.816764802288663 ],
[ 2599.7259021588347 , 769.0082337923552 , - 17.816764802288663 ],
[ 2599.7259021588347 , 769.0082337923552 , - 19.66876480228866 ],
[ 2601.2765123137915 , 767.5669506323393 , - 19.66876480228866 ],
[ 2604.8684867834395 , 771.4313904894723 , - 17.816764802288663 ],
[ 2603.3178766284827 , 772.8726736494882 , - 17.816764802288663 ],
[ 2603.3178766284827 , 772.8726736494882 , - 19.66876480228866 ],
[ 2604.8684867834395 , 771.4313904894723 , - 19.66876480228866 ]
],
"color" : [0 , 0 , 255 ], # バウンディングボックスのRGB色
"label" : "car" , # バウンディングボックスに表示される文字列
"score" : 0.6 # バウンディングボックスに表示される数値
}],
vectors = [
{"start" : [0 , 0 , 0 ], "end" : [0.1 , 0.2 , 0.5 ], "color" : [255 , 0 , 0 ]}, # 色は任意
],
point_cloud_type = "lidar/beta" ,
)})
ポイントクラウドを表示するとき、Controlキーを押しながらマウスを使用すると、内部空間を移動できます。
ポイントクラウドファイル
the from_file method を使用して、ポイントクラウドデータが満載のJSONファイルをロードできます。
run. log({"my_cloud_from_file" : wandb. Object3D. from_file(
"./my_point_cloud.pts.json"
)})
ポイントクラウドデータのフォーマット方法の例を以下に示します。
{
"boxes" : [
{
"color" : [
0 ,
255 ,
0
],
"score" : 0.35 ,
"label" : "My label" ,
"corners" : [
[
2589.695869075582 ,
760.7400443552185 ,
-18.044831294622487
],
[
2590.719039645323 ,
762.3871153874499 ,
-18.044831294622487
],
[
2590.719039645323 ,
762.3871153874499 ,
-19.54083129462249
],
[
2589.695869075582 ,
760.7400443552185 ,
-19.54083129462249
],
[
2594.9666662674313 ,
757.4657929961453 ,
-18.044831294622487
],
[
2595.9898368371723 ,
759.1128640283766 ,
-18.044831294622487
],
[
2595.9898368371723 ,
759.1128640283766 ,
-19.54083129462249
],
[
2594.9666662674313 ,
757.4657929961453 ,
-19.54083129462249
]
]
}
],
"points" : [
[
2566.571924017235 ,
746.7817289698219 ,
-15.269245470863748 ,
76.5 ,
127.5 ,
89.46617199365393
],
[
2566.592983606823 ,
746.6791987335685 ,
-15.275803826279521 ,
76.5 ,
127.5 ,
89.45471117247024
],
[
2566.616361739416 ,
746.4903185513501 ,
-15.28628929674075 ,
76.5 ,
127.5 ,
89.41336375503832
]
],
"type" : "lidar/beta"
}
NumPy配列
上記で定義された配列フォーマット を使用して、numpy配列を直接 the from_numpy method でポイントクラウドを定義できます。
run. log({"my_cloud_from_numpy_xyz" : wandb. Object3D. from_numpy(
np. array(
[
[0.4 , 1 , 1.3 ], # x, y, z
[1 , 1 , 1 ],
[1.2 , 1 , 1.2 ]
]
)
)})
run. log({"my_cloud_from_numpy_cat" : wandb. Object3D. from_numpy(
np. array(
[
[0.4 , 1 , 1.3 , 1 ], # x, y, z, カテゴリ
[1 , 1 , 1 , 1 ],
[1.2 , 1 , 1.2 , 12 ],
[1.2 , 1 , 1.3 , 12 ],
[1.2 , 1 , 1.4 , 12 ],
[1.2 , 1 , 1.5 , 12 ],
[1.2 , 1 , 1.6 , 11 ],
[1.2 , 1 , 1.7 , 11 ],
]
)
)})
run. log({"my_cloud_from_numpy_rgb" : wandb. Object3D. from_numpy(
np. array(
[
[0.4 , 1 , 1.3 , 255 , 0 , 0 ], # x, y, z, r, g, b
[1 , 1 , 1 , 0 , 255 , 0 ],
[1.2 , 1 , 1.3 , 0 , 255 , 255 ],
[1.2 , 1 , 1.4 , 0 , 255 , 255 ],
[1.2 , 1 , 1.5 , 0 , 0 , 255 ],
[1.2 , 1 , 1.1 , 0 , 0 , 255 ],
[1.2 , 1 , 0.9 , 0 , 0 , 255 ],
]
)
)})
wandb. log({"protein" : wandb. Molecule("6lu7.pdb" )})
分子データはpdb、pqr、mmcif、mcif、cif、sdf、sd、gro、mol2、mmtf.のいずれかの10のファイル形式でログできます。
W&Bはまた、SMILES文字列、rdkitmolファイル、rdkit.Chem.rdchem.Molオブジェクトからの分子データのログをサポートします。
resveratrol = rdkit. Chem. MolFromSmiles("Oc1ccc(cc1)C=Cc1cc(O)cc(c1)O" )
wandb. log(
{
"resveratrol" : wandb. Molecule. from_rdkit(resveratrol),
"green fluorescent protein" : wandb. Molecule. from_rdkit("2b3p.mol" ),
"acetaminophen" : wandb. Molecule. from_smiles("CC(=O)Nc1ccc(O)cc1" ),
}
)
runが終了すると、UIで分子の3D可視化と対話できるようになります。
AlphaFoldを使用したライブ例を見る
PNG 画像
wandb.Imagenumpy配列やPILImageのインスタンスをデフォルトでPNGに変換します。
wandb. log({"example" : wandb. Image(... )})
# または複数の画像
wandb. log({"example" : [wandb. Image(... ) for img in images]})
ビデオ
ビデオはwandb.Video
wandb. log({"example" : wandb. Video("myvideo.mp4" )})
現在、メディアブラウザでビデオを見ることができます。 プロジェクトワークスペース、runワークスペース、またはレポートに移動し、Add visualization をクリックしてリッチメディアパネルを追加します。
分子の2Dビュー
wandb.Imagerdkit
molecule = rdkit. Chem. MolFromSmiles("CC(=O)O" )
rdkit. Chem. AllChem. Compute2DCoords(molecule)
rdkit. Chem. AllChem. GenerateDepictionMatching2DStructure(molecule, molecule)
pil_image = rdkit. Chem. Draw. MolToImage(molecule, size= (300 , 300 ))
wandb. log({"acetic_acid" : wandb. Image(pil_image)})
その他のメディア
W&Bは、さまざまな他のメディアタイプのログもサポートしています。
オーディオ
wandb. log({"whale songs" : wandb. Audio(np_array, caption= "OooOoo" , sample_rate= 32 )})
1ステップあたりの最大100のオーディオクリップをログできます。詳細な使い方については、audio-file
ビデオ
wandb. log({"video" : wandb. Video(numpy_array_or_path_to_video, fps= 4 , format= "gif" )})
numpy配列が供給された場合、時間、チャンネル、幅、高さの順であると仮定します。 デフォルトでは4fpsのgif画像を作成します(numpyオブジェクトを渡す場合、ffmpegmoviepy"gif"、"mp4"、"webm"、そして"ogg"です。wandb.Video に文字列を渡すと、ファイルが存在し、wandbにアップロードする前にサポートされたフォーマットであることを確認します。 BytesIOオブジェクトを渡すと、指定されたフォーマットを拡張子とする一時ファイルを作成します。
W&BのRun とProject ページで、メディアセクションにビデオが表示されます。
詳細な使い方については、video-file
テキスト
wandb.Tableを使用して、UIに表示するテーブルにテキストをログします。デフォルトで、列ヘッダーは["Input", "Output", "Expected"]です。最適なUIパフォーマンスを確保するために、デフォルトで最大行数は10,000に設定されています。ただし、ユーザーはwandb.Table.MAX_ROWS = {DESIRED_MAX}を使用して明示的に上限を超えることができます。
columns = ["Text" , "Predicted Sentiment" , "True Sentiment" ]
# メソッド 1
data = [["I love my phone" , "1" , "1" ], ["My phone sucks" , "0" , "-1" ]]
table = wandb. Table(data= data, columns= columns)
wandb. log({"examples" : table})
# メソッド 2
table = wandb. Table(columns= columns)
table. add_data("I love my phone" , "1" , "1" )
table. add_data("My phone sucks" , "0" , "-1" )
wandb. log({"examples" : table})
また、pandas DataFrameオブジェクトを渡すこともできます。
table = wandb. Table(dataframe= my_dataframe)
詳細な使い方については、string
HTML
wandb. log({"custom_file" : wandb. Html(open("some.html" ))})
wandb. log({"custom_string" : wandb. Html('<a href="https://mysite">Link</a>' )})
カスタムHTMLは任意のキーでログ可能で、runページ上にHTMLパネルを接続します。デフォルトではスタイルが注入されます。デフォルトスタイルをオフにするには、inject=Falseを渡します。
wandb. log({"custom_file" : wandb. Html(open("some.html" ), inject= False )})
詳細な使い方については、html-file
2 - モデルをログする
モデルをログする
以下のガイドでは、W&B run にモデルをログし、それと対話する方法を説明します。
以下の API は、実験管理ワークフローの一環としてモデルを追跡するのに便利です。このページに記載されている API を使用して、run にモデルをログし、メトリクス、テーブル、メディア、その他のオブジェクトにアクセスします。
モデル以外にも、データセットやプロンプトなど、シリアライズされたデータの異なるバージョンを作成し追跡したい場合は、W&B Artifacts を使用することをお勧めします。
モデルやその他のオブジェクトを W&B で追跡するための リネージグラフ を探索します。
これらのメソッドで作成されたモデル アーティファクトとの対話(プロパティの更新、メタデータ、エイリアス、説明など)を行います。
W&B Artifacts や高度なバージョン管理ユースケースの詳細については、Artifacts ドキュメントをご覧ください。
モデルを run にログする
log_modellog_model
モデルを W&B run の入力または出力としてマークすると、モデルの依存関係とモデルの関連付けを追跡できます。W&B アプリ UI 内でモデルのリネージを確認します。詳細については、Artifacts チャプターの アーティファクトグラフを探索して移動する ページを参照してください。
モデルファイルが保存されているパスを path パラメータに指定します。パスには、ローカルファイル、ディレクトリ、または s3://bucket/path などの外部バケットへの 参照 URI を指定できます。
<> 内に囲まれた値を自分のもので置き換えることを忘れないでください。
import wandb
W&B run を初期化
run = wandb.init(project="", entity="")
モデルをログする
run.log_model(path="", name="")
オプションで、name パラメータにモデルアーティファクトの名前を指定できます。name が指定されていない場合、W&B は入力パスのベース名に run ID をプレフィックスとして使用して名前を生成します。
モデルに W&B が割り当てた
name またはユーザーが指定した
nameを追跡してください。モデルのパスを取得するには、
use_model メソッドでモデルの名前が必要です。
log_model の詳細については、API リファレンスガイドを参照してください。
例: モデルを run にログする
import os
import wandb
from tensorflow import keras
from tensorflow.keras import layers
config = {"optimizer" : "adam" , "loss" : "categorical_crossentropy" }
# W&B run を初期化
run = wandb. init(entity= "charlie" , project= "mnist-experiments" , config= config)
# ハイパーパラメーター
loss = run. config["loss" ]
optimizer = run. config["optimizer" ]
metrics = ["accuracy" ]
num_classes = 10
input_shape = (28 , 28 , 1 )
# トレーニング アルゴリズム
model = keras. Sequential(
[
layers. Input(shape= input_shape),
layers. Conv2D(32 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Conv2D(64 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Flatten(),
layers. Dropout(0.5 ),
layers. Dense(num_classes, activation= "softmax" ),
]
)
# トレーニング用のモデルを設定
model. compile(loss= loss, optimizer= optimizer, metrics= metrics)
# モデルを保存
model_filename = "model.h5"
local_filepath = "./"
full_path = os. path. join(local_filepath, model_filename)
model. save(filepath= full_path)
# モデルを W&B run にログする
run. log_model(path= full_path, name= "MNIST" )
run. finish()
ユーザーが log_model を呼び出したとき、MNISTという名前のモデルアーティファクトが作成され、ファイル model.h5 がモデルアーティファクトに追加されました。あなたのターミナルまたはノートブックは、モデルがログされた run に関する情報を見つける場所についての情報を出力します。
View run different- surf- 5 at: https:// wandb. ai/ charlie/ mnist- experiments/ runs/ wlby6fuw
Synced 5 W& B file(s), 0 media file(s), 1 artifact file(s) and 0 other file(s)
Find logs at: ./ wandb/ run- 20231206_103511 - wlby6fuw/ logs
ログされたモデルをダウンロードして使用する
以前に W&B run にログされたモデルファイルにアクセスしてダウンロードするには、use_model
取得したいモデルファイルが保存されているモデルアーティファクトの名前を指定します。提供した名前は、既存のログされたモデルアーティファクトの名前と一致している必要があります。
最初に log_model でファイルをログした際に name を定義しなかった場合、割り当てられたデフォルト名は、入力パスのベース名にrun ID をプレフィックスとして付けたものになります。
<> 内に囲まれた他の値を自分のもので置き換えることを忘れないでください。
import wandb
# run を初期化
run = wandb. init(project= "<your-project>" , entity= "<your-entity>" )
# モデルにアクセスしてダウンロードする。ダウンロードされたアーティファクトのパスが返されます
downloaded_model_path = run. use_model(name= "<your-model-name>" )
use_modeldownloaded_model_path という変数に保存されています。
例: ログされたモデルをダウンロードして使用する
たとえば、以下のコードスニペットでは、ユーザーが use_model API を呼び出しています。彼らは取得したいモデルアーティファクトの名前を指定し、またバージョン/エイリアスも提供しています。そして、API から返されるパスを downloaded_model_path 変数に保存しました。
import wandb
entity = "luka"
project = "NLP_Experiments"
alias = "latest" # モデルバージョンのセマンティックなニックネームまたは識別子
model_artifact_name = "fine-tuned-model"
# run を初期化
run = wandb. init(project= project, entity= entity)
# モデルにアクセスしてダウンロードする。ダウンロードされたアーティファクトのパスが返されます
downloaded_model_path = run. use_model(name = f " { model_artifact_name} : { alias} " )
use_model
モデルを W&B モデルレジストリにログしリンクする
link_model メソッドは、現在のところレガシー W&B モデルレジストリとしか互換性がありませんが、これは間もなく廃止される予定です。モデルアーティファクトを新しいバージョンのモデルレジストリにリンクする方法については、レジストリの
ドキュメント をご覧ください。
link_modelW&B モデルレジストリ にリンクします。登録されたモデルが存在しない場合、W&B は registered_model_name パラメータにあなたが提供した名前で新しいものを作成します。
モデルをリンクすることは、他のチームメンバーが視聴および利用できる中央集権的なチームのリポジトリにモデルを「ブックマーク」または「公開」することに類似しています。
モデルをリンクすると、そのモデルは Registry に重複されることも、プロジェクトから移動してレジストリに入れられることもありません。リンクされたモデルは、プロジェクト内の元のモデルへのポインターです。
Registry を使用して、タスクごとに最高のモデルを整理したり、モデルのライフサイクルを管理したり、MLライフサイクル全体での追跡や監査を容易にしたり、Webhooks やジョブでの下流アクションを自動化 することができます。
Registered Model は、Model Registry にリンクされたモデルバージョンのコレクションまたはフォルダーです。登録されたモデルは通常、単一のモデリングユースケースまたはタスクの候補モデルを表します。
以下のコードスニペットは、link_model API を使用してモデルをリンクする方法を示しています。<> 内に囲まれた他の値を自分のもので置き換えることを忘れないでください。
import wandb
run = wandb. init(entity= "<your-entity>" , project= "<your-project>" )
run. link_model(path= "<path-to-model>" , registered_model_name= "<registered-model-name>" )
run. finish()
link_model API リファレンスガイドでは、オプションのパラメータに関する詳細情報が記載されています。
registered-model-name が Model Registry 内に既に存在する登録済みのモデル名と一致する場合、そのモデルはその登録済みモデルにリンクされます。そのような登録済みモデルが存在しない場合、新しいものが作成され、そのモデルが最初にリンクされます。
例えば、既に Model Registry に “Fine-Tuned-Review-Autocompletion"という名前の登録済みモデルが存在し、いくつかのモデルバージョンが既にリンクされていると仮定します: v0, v1, v2。link_model を registered-model-name="Fine-Tuned-Review-Autocompletion"を使用して呼び出した場合、新しいモデルは既存の登録済みモデルに v3 としてリンクされます。この名前の登録済みモデルが存在しない場合、新しいものが作成され、新しいモデルが v0 としてリンクされます。
例: モデルを W&B モデルレジストリにログしリンクする
例えば、以下のコードスニペットでは、モデルファイルをログし、登録済みのモデル名 "Fine-Tuned-Review-Autocompletion"にモデルをリンクする方法を示しています。
これを行うために、ユーザーは link_model API を呼び出します。API を呼び出す際に、モデルの内容を示すローカルファイルパス (path) と、リンクするための登録済みモデルの名前 (registered_model_name) を提供します。
import wandb
path = "/local/dir/model.pt"
registered_model_name = "Fine-Tuned-Review-Autocompletion"
run = wandb. init(project= "llm-evaluation" , entity= "noa" )
run. link_model(path= path, registered_model_name= registered_model_name)
run. finish()
リマインダー: 登録済みモデルは、ブックマークされたモデルバージョンのコレクションを管理します。
3 - ログ テーブル
W&B でテーブルをログします。
wandb.Table を使って、データをログに記録し W&B で視覚化・クエリできるようにします。このガイドでは次のことを学びます:
テーブルを作成する データを追加する データを取得する テーブルを保存する
テーブルを作成する
Table(テーブル)を定義するには、各データ行に表示したい列を指定します。各行はトレーニングデータセットの単一の項目、トレーニング中の特定のステップやエポック、テスト項目でのモデルの予測、モデルが生成したオブジェクトなどです。各列には固定の型があり、数値、テキスト、ブール値、画像、ビデオ、オーディオなどがあります。あらかじめ型を指定する必要はありません。各列に名前を付け、その型のデータのみをその列のインデックスに渡してください。より詳細な例については、このレポート を参照してください。
wandb.Table コンストラクタを次の2つの方法のいずれかで使用します:
行のリスト: 名前付きの列とデータの行をログに記録します。例えば、次のコードスニペットは 2 行 3 列のテーブルを生成します:
wandb. Table(columns= ["a" , "b" , "c" ], data= [["1a" , "1b" , "1c" ], ["2a" , "2b" , "2c" ]])
Pandas DataFrame: wandb.Table(dataframe=my_df) を使用して DataFrame をログに記録します。列の名前は DataFrame から抽出されます。
既存の配列またはデータフレームから
# モデルが4つの画像で予測を返したと仮定します
# 次のフィールドが利用可能です:
# - 画像ID
# - 画像ピクセル(wandb.Image() でラップ)
# - モデルの予測ラベル
# - 正解ラベル
my_data = [
[0 , wandb. Image("img_0.jpg" ), 0 , 0 ],
[1 , wandb. Image("img_1.jpg" ), 8 , 0 ],
[2 , wandb. Image("img_2.jpg" ), 7 , 1 ],
[3 , wandb. Image("img_3.jpg" ), 1 , 1 ],
]
# 対応する列で wandb.Table() を作成
columns = ["id" , "image" , "prediction" , "truth" ]
test_table = wandb. Table(data= my_data, columns= columns)
データを追加する
Tables は可変です。スクリプトが実行中に最大 200,000 行までテーブルにデータを追加できます。テーブルにデータを追加する方法は2つあります:
行を追加する : table.add_data("3a", "3b", "3c")。新しい行はリストとして表現されないことに注意してください。行がリスト形式の場合は * を使ってリストを位置引数に展開します: table.add_data(*my_row_list)。行にはテーブルの列数と同じ数のエントリが含まれている必要があります。列を追加する : table.add_column(name="col_name", data=col_data)。col_data の長さは現在のテーブルの行数と同じである必要があります。ここで col_data はリストデータや NumPy NDArray でも構いません。
データを段階的に追加する
このコードサンプルは、次第に W&B テーブルを作成し、データを追加する方法を示しています。信頼度スコアを含む事前定義された列でテーブルを定義し、推論中に行ごとにデータを追加します。また、run を再開するときにテーブルにデータを段階的に追加 することもできます。
# 各ラベルの信頼度スコアを含むテーブルの列を定義
columns = ["id" , "image" , "guess" , "truth" ]
for digit in range(10 ): # 各数字 (0-9) に対する信頼度スコア列を追加
columns. append(f "score_ { digit} " )
# 定義された列でテーブルを初期化
test_table = wandb. Table(columns= columns)
# テストデータセットを通過し、データを行ごとにテーブルに追加
# 各行は画像 ID、画像、予測されたラベル、正解ラベル、信頼度スコアを含みます
for img_id, img in enumerate(mnist_test_data):
true_label = mnist_test_data_labels[img_id] # 正解ラベル
guess_label = my_model. predict(img) # 予測ラベル
test_table. add_data(
img_id, wandb. Image(img), guess_label, true_label
) # テーブルに行データを追加
Run を再開した際にデータを追加
再開した Run において、既存のテーブルをアーティファクトから読み込み、最後のデータ行を取得して、更新されたメトリクスを追加することで W&B テーブルを段階的に更新できます。次に、互換性を保つためにテーブルを再初期化し、更新されたバージョンを W&B に再度ログに記録します。
# アーティファクトから既存のテーブルを読み込む
best_checkpt_table = wandb. use_artifact(table_tag). get(table_name)
# 再開のためにテーブルの最後のデータ行を取得
best_iter, best_metric_max, best_metric_min = best_checkpt_table. data[- 1 ]
# 必要に応じて最高のメトリクスを更新
# テーブルに更新されたデータを追加
best_checkpt_table. add_data(best_iter, best_metric_max, best_metric_min)
# 更新されたデータでテーブルを再初期化し、互換性を確保
best_checkpt_table = wandb. Table(
columns= ["col1" , "col2" , "col3" ], data= best_checkpt_table. data
)
# 更新されたテーブルを Weights & Biases にログする
wandb. log({table_name: best_checkpt_table})
データを取得する
データが Table にあるとき、列または行ごとにアクセスできます:
行イテレータ : ユーザーは Table の行イテレータを利用して、for ndx, row in table.iterrows(): ... のようにデータの行を効率的に反復処理できます。列を取得する : ユーザーは table.get_column("col_name") を使用してデータの列を取得できます。convert_to="numpy" を渡すと、列を NumPy のプリミティブ NDArray に変換できます。これは、列に wandb.Image などのメディアタイプが含まれている場合に、基になるデータに直接アクセスするのに便利です。
テーブルを保存する
スクリプトでモデルの予測のテーブルなどのデータを生成した後、それを W&B に保存して結果をリアルタイムで視覚化します。
Run にテーブルをログする
wandb.log() を使用してテーブルを Run に保存します:
run = wandb. init()
my_table = wandb. Table(columns= ["a" , "b" ], data= [["1a" , "1b" ], ["2a" , "2b" ]])
run. log({"table_key" : my_table})
同じキーにテーブルがログに記録されるたびに、新しいバージョンのテーブルが作成され、バックエンドに保存されます。これにより、複数のトレーニングステップにわたって同じテーブルをログに記録し、モデルの予測がどのように向上するかを確認したり、異なる Run 間でテーブルを比較したりすることができます。同じテーブルに最大 200,000 行までログに記録できます。
200,000 行以上をログに記録するには、以下のように制限をオーバーライドできます:
wandb.Table.MAX_ARTIFACT_ROWS = X
ただし、これにより UI でのクエリの速度低下などのパフォーマンス問題が発生する可能性があります。
プログラムによるテーブルへのアクセス
バックエンドでは、Tables は Artifacts として保存されています。特定のバージョンにアクセスする場合は、artifact API を使用して行うことができます:
with wandb. init() as run:
my_table = run. use_artifact("run-<run-id>-<table-name>:<tag>" ). get("<table-name>" )
Artifacts の詳細については、デベロッパーガイドの Artifacts チャプター を参照してください。
テーブルを視覚化する
この方法でログに記録されたテーブルは、Run ページと Project ページの両方でワークスペースに表示されます。詳細については、テーブルの視覚化と分析 を参照してください。
アーティファクトテーブル
artifact.add() を使用して、テーブルをワークスペースの代わりに Run の Artifacts セクションにログします。これは、データセットを1回ログに記録し、今後の Run のために参照したい場合に役立ちます。
run = wandb. init(project= "my_project" )
# 各重要なステップのために wandb Artifact を作成
test_predictions = wandb. Artifact("mnist_test_preds" , type= "predictions" )
# [上記のように予測データを構築]
test_table = wandb. Table(data= data, columns= columns)
test_predictions. add(test_table, "my_test_key" )
run. log_artifact(test_predictions)
画像データを使用した artifact.add() の詳細な例については、この Colab を参照してください: 画像データを使った artifact.add() の詳細な例 また Artifacts と Tables を使ったバージョン管理と重複排除データの例 に関してはこのレポートを参照してください。
アーティファクトテーブルを結合する
wandb.JoinedTable(table_1, table_2, join_key) を使用して、ローカルに構築したテーブルや他のアーティファクトから取得したテーブルを結合できます。
引数
説明
table_1
(str, wandb.Table, ArtifactEntry) アーティファクト内の wandb.Table へのパス、テーブルオブジェクト、または ArtifactEntry
table_2
(str, wandb.Table, ArtifactEntry) アーティファクト内の wandb.Table へのパス、テーブルオブジェクト、または ArtifactEntry
join_key
(str, [str, str]) 結合を行うキーまたはキーのリスト
以前にアーティファクトコンテキストでログに記録した2つのテーブルを結合するには、アーティファクトからそれらを取得し、新しいテーブルに結合した結果を格納します。この例では、'original_songs' という名前のオリジナルの曲のテーブルと 'synth_songs' という名前の同じ曲の合成バージョンのテーブルを結合する方法を示しています。以下のコード例は 2 つのテーブルを "song_id" で結合し、結果のテーブルを新しい W&B テーブルとしてアップロードします:
import wandb
run = wandb. init(project= "my_project" )
# オリジナルの曲のテーブルを取得
orig_songs = run. use_artifact("original_songs:latest" )
orig_table = orig_songs. get("original_samples" )
# 合成曲のテーブルを取得
synth_songs = run. use_artifact("synth_songs:latest" )
synth_table = synth_songs. get("synth_samples" )
# "song_id" でテーブルを結合
join_table = wandb. JoinedTable(orig_table, synth_table, "song_id" )
join_at = wandb. Artifact("synth_summary" , "analysis" )
# テーブルをアーティファクトに追加し W&B にログする
join_at. add(join_table, "synth_explore" )
run. log_artifact(join_at)
このチュートリアルを読む と、異なるアーティファクトオブジェクトに保存された 2 つのテーブルを組み合わせる方法の例が示されています。
4 - ログサマリーメトリクス
時間とともに変化する値に加えて、モデルや前処理ステップを要約する単一の値を追跡することも重要です。この情報を W&B Run の summary 辞書にログします。Run の summary 辞書は numpy 配列、PyTorch テンソル、TensorFlow テンソルを扱うことができます。値がこれらのタイプのいずれかの場合、バイナリファイルにテンソル全体を保存し、メトリクスを summary オブジェクトに保存します。たとえば最小値、平均、分散、パーセンタイルなどです。
最後に wandb.log でログされた値は、自動的に W&B Run の summary 辞書に設定されます。summary メトリクス辞書が変更されると、以前の値は失われます。
次のコードスニペットは、W&B にカスタムの summary メトリクスを提供する方法を示しています。
wandb. init(config= args)
best_accuracy = 0
for epoch in range(1 , args. epochs + 1 ):
test_loss, test_accuracy = test()
if test_accuracy > best_accuracy:
wandb. summary["best_accuracy" ] = test_accuracy
best_accuracy = test_accuracy
トレーニングが完了した後、既存の W&B Run の summary 属性を更新することができます。W&B Public API を使用して、summary 属性を更新してください。
api = wandb. Api()
run = api. run("username/project/run_id" )
run. summary["tensor" ] = np. random. random(1000 )
run. summary. update()
summary メトリクスをカスタマイズする
カスタム summary メトリクスは、トレーニングにおける最良のステップでのモデルのパフォーマンスを wandb.summary にキャプチャするのに便利です。たとえば、最終的な値の代わりに、最大精度や最小損失値をキャプチャしたいかもしれません。
デフォルトでは、summary は履歴からの最終的な値を使用します。summary メトリクスをカスタマイズするには、define_metric の中に summary 引数を渡します。以下の値を受け付けます。
"min""max""mean""best""last""none"
"best" を使用するには、任意の objective 引数を "minimize" または "maximize" に設定する必要があります。
次の例は、損失と精度の最小値と最大値を summary に追加する方法を示しています。
import wandb
import random
random. seed(1 )
wandb. init()
# 損失の最小値および最大値を summary に追加
wandb. define_metric("loss" , summary= "min" )
wandb. define_metric("loss" , summary= "max" )
# 精度の最小値および最大値を summary に追加
wandb. define_metric("acc" , summary= "min" )
wandb. define_metric("acc" , summary= "max" )
for i in range(10 ):
log_dict = {
"loss" : random. uniform(0 , 1 / (i + 1 )),
"acc" : random. uniform(1 / (i + 1 ), 1 ),
}
wandb. log(log_dict)
summary メトリクスを閲覧する
Run の Overview ページまたはプロジェクトの runs テーブルで summary 値を表示することができます。
Run Overview
Run Table
W&B Public API
W&B アプリに移動します。
Workspace タブを選択します。runs のリストから、summary 値をログした run の名前をクリックします。
Overview タブを選択します。Summary セクションで summary 値を表示します。
W&B アプリに移動します。
Runs タブを選択します。runs テーブル内で、summary 値の名前に基づいて列内の summary 値を表示することができます。
W&B Public API を使用して、run の summary 値を取得することができます。
次のコード例は、W&B Public API と pandas を使用して特定の run にログされた summary 値を取得する方法の一例を示しています。
import wandb
import pandas
entity = "<your-entity>"
project = "<your-project>"
run_name = "<your-run-name>" # summary 値を持つ run の名前
all_runs = []
for run in api. runs(f " { entity} / { project_name} " ):
print("Fetching details for run: " , run. id, run. name)
run_data = {
"id" : run. id,
"name" : run. name,
"url" : run. url,
"state" : run. state,
"tags" : run. tags,
"config" : run. config,
"created_at" : run. created_at,
"system_metrics" : run. system_metrics,
"summary" : run. summary,
"project" : run. project,
"entity" : run. entity,
"user" : run. user,
"path" : run. path,
"notes" : run. notes,
"read_only" : run. read_only,
"history_keys" : run. history_keys,
"metadata" : run. metadata,
}
all_runs. append(run_data)
# DataFrame に変換
df = pd. DataFrame(all_runs)
# 列名(run)に基づいて行を取得し、辞書に変換
df[df['name' ]== run_name]. summary. reset_index(drop= True ). to_dict()
5 - ログ軸をカスタマイズする
define_metric を使用してカスタム x 軸 を設定します。 カスタム x 軸は、トレーニング中に過去の異なるタイムステップに非同期でログを記録する必要がある場合に便利です。たとえば、RL ではエピソードごとの報酬やステップごとの報酬を追跡する場合に役立ちます。
Google Colab で define_metric を試す →
軸をカスタマイズする
デフォルトでは、すべてのメトリクスは同じ x 軸に対してログが記録されます。これは、 W&B 内部の step です。時には、以前のステップにログを記録したい場合や、別の x 軸を使用したい場合があります。
以下は、デフォルトのステップの代わりにカスタムの x 軸メトリクスを設定する例です。
import wandb
wandb. init()
# カスタム x 軸メトリクスを定義
wandb. define_metric("custom_step" )
# どのメトリクスがそれに対してプロットされるかを定義
wandb. define_metric("validation_loss" , step_metric= "custom_step" )
for i in range(10 ):
log_dict = {
"train_loss" : 1 / (i + 1 ),
"custom_step" : i** 2 ,
"validation_loss" : 1 / (i + 1 ),
}
wandb. log(log_dict)
x 軸はグロブを使用して設定することもできます。現在、文字列のプレフィックスを持つグロブのみが使用可能です。次の例では、プレフィックス "train/" を持つすべてのログされたメトリクスを、x 軸 "train/step" にプロットします:
import wandb
wandb. init()
# カスタム x 軸メトリクスを定義
wandb. define_metric("train/step" )
# 他のすべての train/ メトリクスをこのステップに使用するように設定
wandb. define_metric("train/*" , step_metric= "train/step" )
for i in range(10 ):
log_dict = {
"train/step" : 2 ** i, # W&B 内部ステップと指数的な成長
"train/loss" : 1 / (i + 1 ), # x 軸は train/step
"train/accuracy" : 1 - (1 / (1 + i)), # x 軸は train/step
"val/loss" : 1 / (1 + i), # x 軸は内部 wandb ステップ
}
wandb. log(log_dict)
6 - 実験からプロットを作成して追跡する
機械学習実験からプロットを作成し、追跡する。
Using the methods in wandb.plot, you can track charts with wandb.log, including charts that change over time during training. To learn more about our custom charting framework, check out this guide .
Basic charts
これらのシンプルなチャートにより、メトリクスと結果の基本的な可視化を簡単に構築できます。
Line
Scatter
Bar
Histogram
Multi-line
wandb.plot.line()
カスタムなラインプロット、任意の軸上で順序付けられたポイントのリストをログします。
data = [[x, y] for (x, y) in zip(x_values, y_values)]
table = wandb. Table(data= data, columns= ["x" , "y" ])
wandb. log(
{
"my_custom_plot_id" : wandb. plot. line(
table, "x" , "y" , title= "Custom Y vs X Line Plot"
)
}
)
これは任意の2次元軸に曲線をログするために使用できます。二つの値のリストをプロットする場合、リスト内の値の数は正確に一致する必要があります。例えば、それぞれのポイントはxとyを持っている必要があります。
See in the app
Run the code
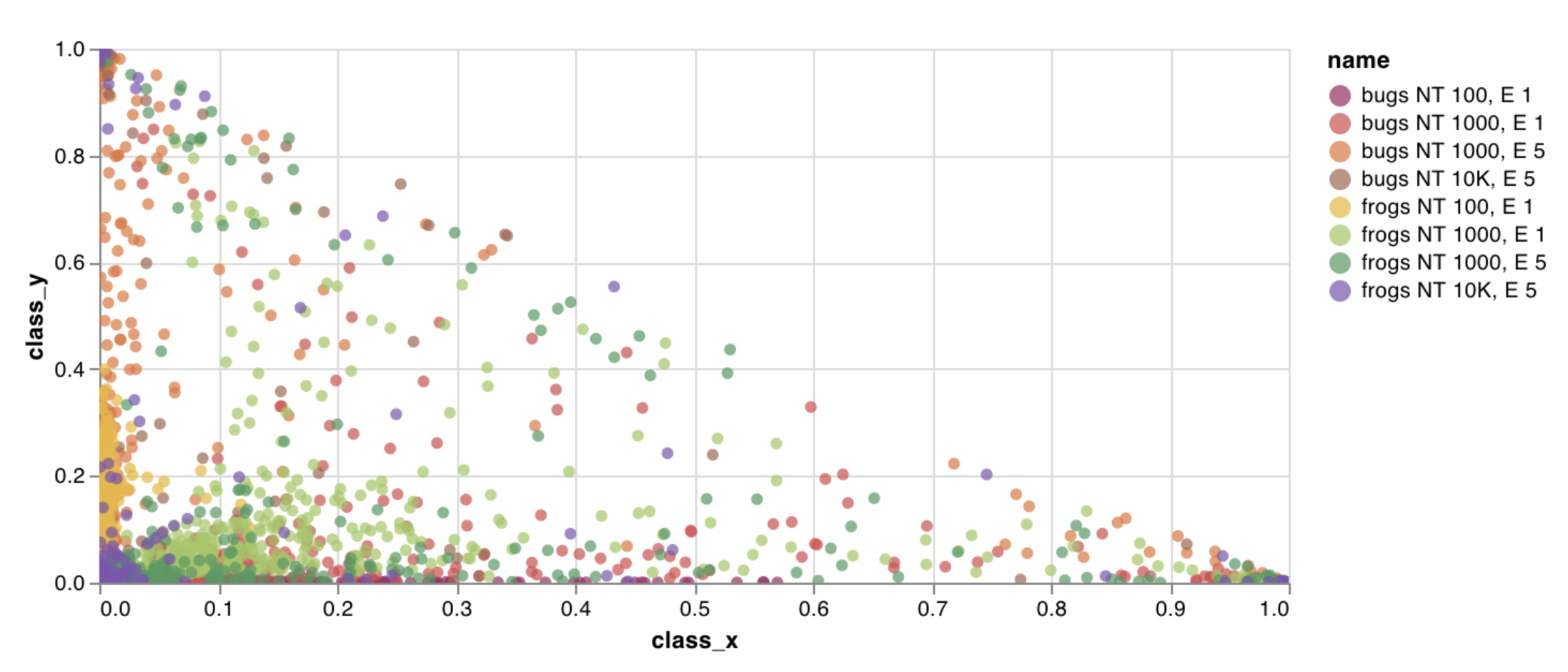
wandb.plot.scatter()
カスタムな散布図をログします—任意の軸xとy上のポイント(x, y)のリスト。
data = [[x, y] for (x, y) in zip(class_x_scores, class_y_scores)]
table = wandb. Table(data= data, columns= ["class_x" , "class_y" ])
wandb. log({"my_custom_id" : wandb. plot. scatter(table, "class_x" , "class_y" )})
これは任意の2次元軸に散布ポイントをログするために使用できます。二つの値のリストをプロットする場合、リスト内の値の数は正確に一致する必要があります。例えば、それぞれのポイントはxとyを持っている必要があります。
See in the app
Run the code
wandb.plot.bar()
カスタムな棒グラフをログします—数行でバーとしてラベル付けされた値のリストをネイティブに:
data = [[label, val] for (label, val) in zip(labels, values)]
table = wandb. Table(data= data, columns= ["label" , "value" ])
wandb. log(
{
"my_bar_chart_id" : wandb. plot. bar(
table, "label" , "value" , title= "Custom Bar Chart"
)
}
)
これは任意の棒グラフをログするために使用できます。リスト内のラベルと値の数は正確に一致する必要があります。それぞれのデータポイントは両方を持たなければなりません。
See in the app
Run the code
wandb.plot.histogram()
カスタムなヒストグラムをログします—発生のカウント/頻度でリスト内の値をビンへソートします—数行でネイティブに。予測信頼度スコア(scores)のリストがあって、その分布を可視化したいとします。
data = [[s] for s in scores]
table = wandb. Table(data= data, columns= ["scores" ])
wandb. log({"my_histogram" : wandb. plot. histogram(table, "scores" , title= "Histogram" )})
これは任意のヒストグラムをログするために使用できます。dataはリストのリストで、行と列の2次元配列をサポートすることを意図しています。
See in the app
Run the code
wandb.plot.line_series()
複数の線、または複数の異なるx-y座標ペアのリストを一つの共有x-y軸上にプロットします:
wandb. log(
{
"my_custom_id" : wandb. plot. line_series(
xs= [0 , 1 , 2 , 3 , 4 ],
ys= [[10 , 20 , 30 , 40 , 50 ], [0.5 , 11 , 72 , 3 , 41 ]],
keys= ["metric Y" , "metric Z" ],
title= "Two Random Metrics" ,
xname= "x units" ,
)
}
)
xとyのポイントの数は正確に一致する必要があることに注意してください。複数のy値のリストに合ったx値のリストを一つ提供することも、または各y値のリストに対して個別のx値のリストを提供することもできます。
See in the app
Model evaluation charts
これらのプリセットチャートは、wandb.plotメソッド内蔵で、スクリプトからチャートを直接ログして、UIで正確に確認したい情報をすぐに把握できます。
Precision-recall curves
ROC curves
Confusion matrix
wandb.plot.pr_curve()
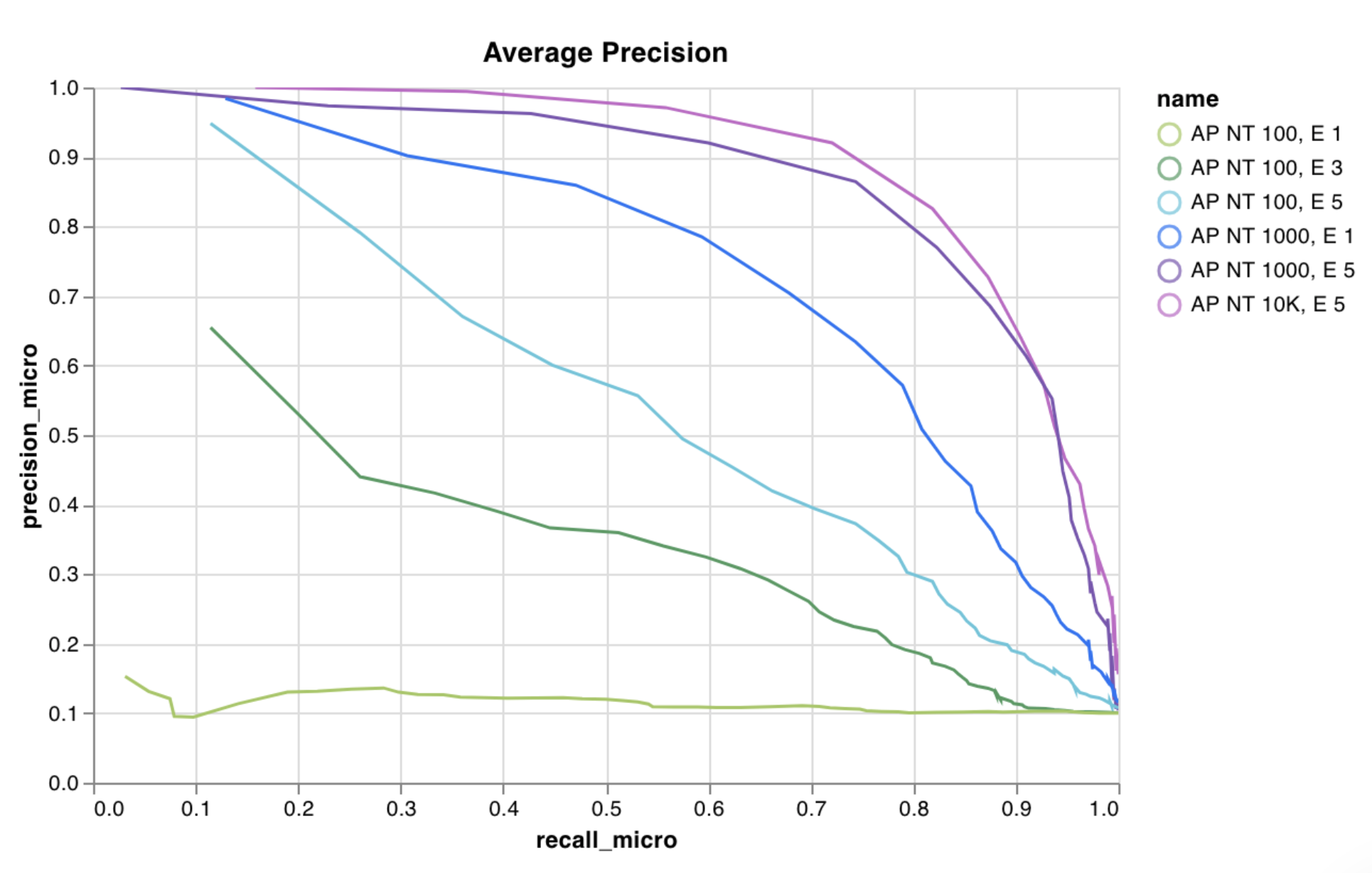
Precision-Recall curve を1行で作成します:
wandb. log({"pr" : wandb. plot. pr_curve(ground_truth, predictions)})
コードが以下のものにアクセスできるときに、これをログできます:
一連の例に対するモデルの予測スコア(predictions)
それらの例に対応する正解ラベル(ground_truth)
(オプションで)ラベル/クラス名のリスト(labels=["cat", "dog", "bird"...] で、ラベルインデックスが0はcat、1はdog、2はbirdを意味するなど)
(オプションで)プロットで可視化するラベルのサブセット
See in the app
Run the code
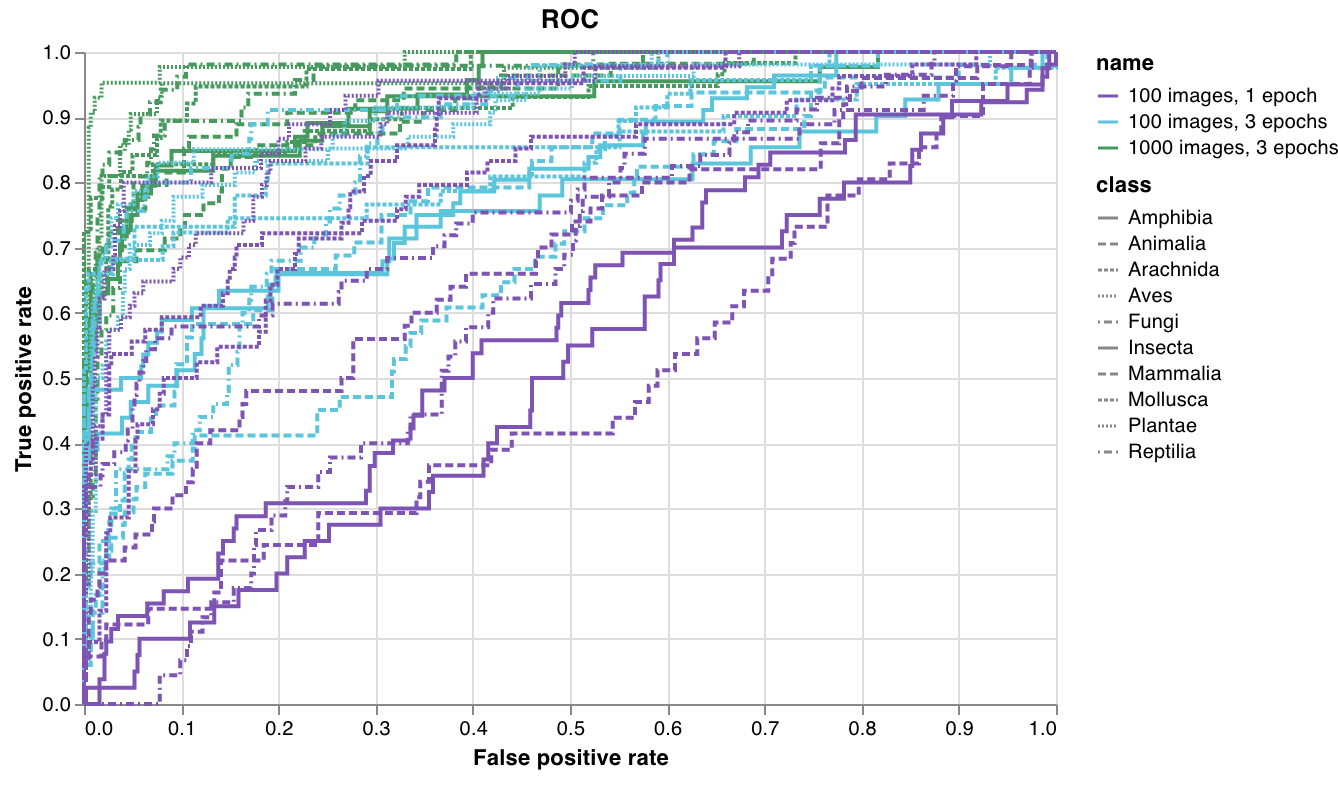
wandb.plot.roc_curve()
ROC curve を1行で作成します:
wandb. log({"roc" : wandb. plot. roc_curve(ground_truth, predictions)})
コードが以下のものにアクセスできるときに、これをログできます:
一連の例に対するモデルの予測スコア(predictions)
それらの例に対応する正解ラベル(ground_truth)
(オプションで)ラベル/クラス名のリスト(labels=["cat", "dog", "bird"...] で、ラベルインデックスが0はcat、1はdog、2はbirdを意味するなど)
(オプションで)プロットで可視化するラベルのサブセット(まだリスト形式)
See in the app
Run the code
wandb.plot.confusion_matrix()
マルチクラスの混同行列 を1行で作成します:
cm = wandb. plot. confusion_matrix(
y_true= ground_truth, preds= predictions, class_names= class_names
)
wandb. log({"conf_mat" : cm})
コードが以下のものにアクセスできるときに、これをログできます:
一連の例に対するモデルの予測ラベル(preds)または正規化された確率スコア(probs)。確率は(例の数、クラスの数)という形でなければなりません。確率または予測のどちらでも良いですが両方を提供することはできません。
それらの例に対応する正解ラベル(y_true)
文字列のラベル/クラス名のフルリスト(例:class_names=["cat", "dog", "bird"] で、インデックス0がcat、1がdog、2がbirdである場合)
See in the app
Run the code
Interactive custom charts
完全なカスタマイズを行う場合、内蔵のCustom Chart preset を調整するか、新しいプリセットを作成し、チャートを保存します。チャートIDを使用して、そのカスタムプリセットに直接スクリプトからデータをログします。
# 作成したい列を持つテーブルを作成
table = wandb. Table(data= data, columns= ["step" , "height" ])
# テーブルの列からチャートのフィールドへマップ
fields = {"x" : "step" , "value" : "height" }
# 新しいカスタムチャートプリセットにテーブルを使用
# 自分の保存したチャートプリセットを使用するには、vega_spec_nameを変更
# タイトルを編集するには、string_fieldsを変更
my_custom_chart = wandb. plot_table(
vega_spec_name= "carey/new_chart" ,
data_table= table,
fields= fields,
string_fields= {"title" : "Height Histogram" },
)
Run the code
Matplotlib and Plotly plots
W&BのCustom Charts をwandb.plotで使用する代わりに、matplotlib やPlotly で生成されたチャートをログすることができます。
import matplotlib.pyplot as plt
plt. plot([1 , 2 , 3 , 4 ])
plt. ylabel("some interesting numbers" )
wandb. log({"chart" : plt})
matplotlibプロットまたは図オブジェクトをwandb.log()に渡すだけです。デフォルトでは、プロットをPlotly プロットに変換します。プロットを画像としてログしたい場合はwandb.Imageにプロットを渡すことができます。Plotlyチャートを直接受け入れることもできます。
「空のプロットをログしようとしました」というエラーが発生した場合は、プロットとは別に図をfig = plt.figure()として保存してから、wandb.logでfigをログできます。
Log custom HTML to W&B Tables
W&Bでは、PlotlyやBokehからインタラクティブなチャートをHTMLとしてログし、Tablesに追加することをサポートしています。
インタラクティブなPlotlyチャートをwandb TablesにHTML形式でログできます。
import wandb
import plotly.express as px
# 新しいrunを初期化
run = wandb. init(project= "log-plotly-fig-tables" , name= "plotly_html" )
# テーブルを作成
table = wandb. Table(columns= ["plotly_figure" ])
# Plotly図のパスを作成
path_to_plotly_html = "./plotly_figure.html"
# 例のPlotly図
fig = px. scatter(x= [0 , 1 , 2 , 3 , 4 ], y= [0 , 1 , 4 , 9 , 16 ])
# Plotly図をHTMLに書き込み
# auto_playをFalseに設定すると、アニメーション付きのPlotlyチャートが自動的にテーブル内で再生されないようにします
fig. write_html(path_to_plotly_html, auto_play= False )
# Plotly図をHTMLファイルとしてTableに追加
table. add_data(wandb. Html(path_to_plotly_html))
# Tableをログ
run. log({"test_table" : table})
wandb. finish()
インタラクティブなBokehチャートをwandb TablesにHTML形式でログできます。
from scipy.signal import spectrogram
import holoviews as hv
import panel as pn
from scipy.io import wavfile
import numpy as np
from bokeh.resources import INLINE
hv. extension("bokeh" , logo= False )
import wandb
def save_audio_with_bokeh_plot_to_html (audio_path, html_file_name):
sr, wav_data = wavfile. read(audio_path)
duration = len(wav_data) / sr
f, t, sxx = spectrogram(wav_data, sr)
spec_gram = hv. Image((t, f, np. log10(sxx)), ["Time (s)" , "Frequency (hz)" ]). opts(
width= 500 , height= 150 , labelled= []
)
audio = pn. pane. Audio(wav_data, sample_rate= sr, name= "Audio" , throttle= 500 )
slider = pn. widgets. FloatSlider(end= duration, visible= False )
line = hv. VLine(0 ). opts(color= "white" )
slider. jslink(audio, value= "time" , bidirectional= True )
slider. jslink(line, value= "glyph.location" )
combined = pn. Row(audio, spec_gram * line, slider). save(html_file_name)
html_file_name = "audio_with_plot.html"
audio_path = "hello.wav"
save_audio_with_bokeh_plot_to_html(audio_path, html_file_name)
wandb_html = wandb. Html(html_file_name)
run = wandb. init(project= "audio_test" )
my_table = wandb. Table(columns= ["audio_with_plot" ], data= [[wandb_html], [wandb_html]])
run. log({"audio_table" : my_table})
run. finish()
7 - 実験管理で CSV ファイルを追跡する
W&B にデータをインポートしてログする方法
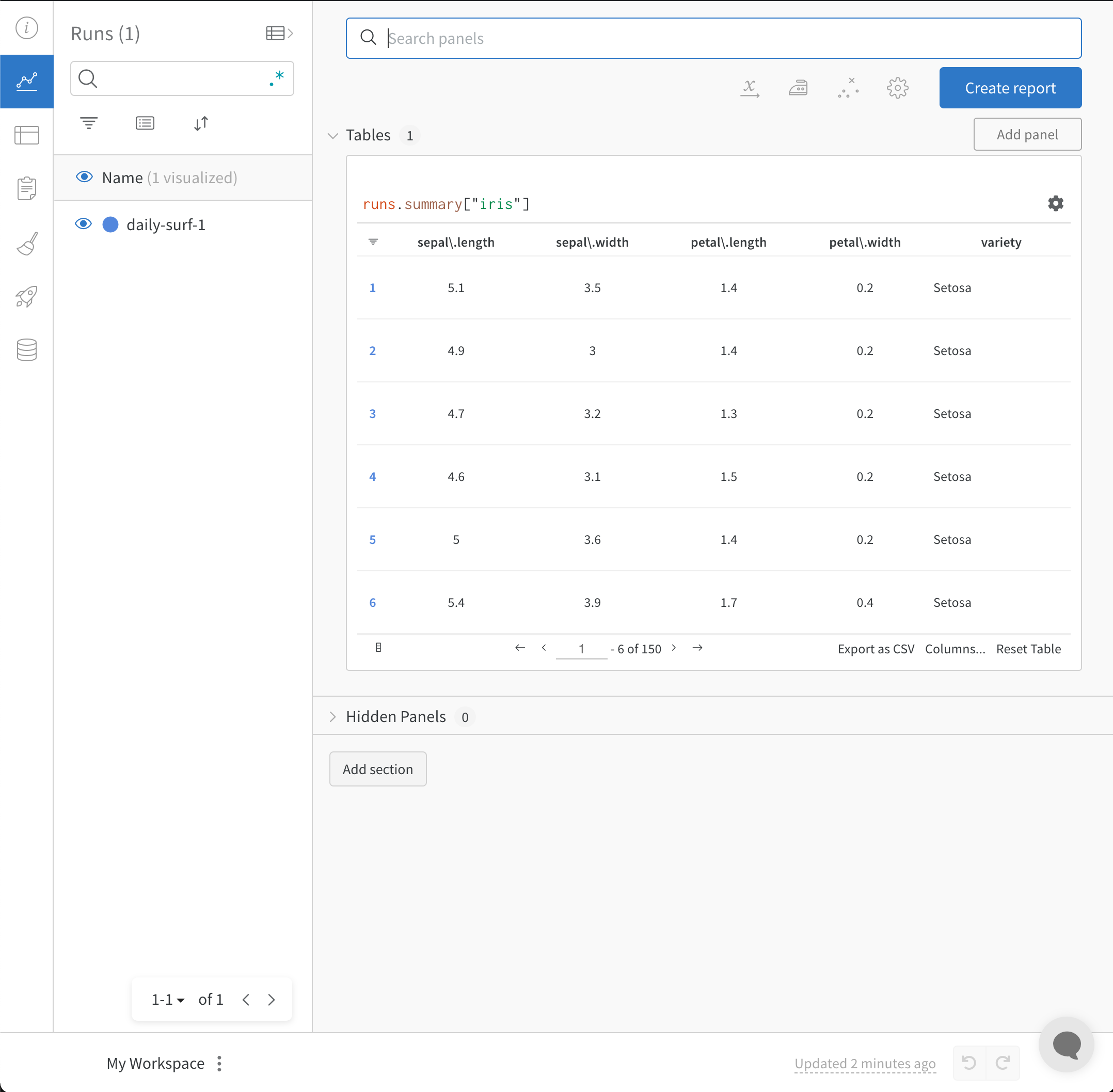
W&B Python ライブラリを使用して、CSV ファイルをログし、W&B ダッシュボード で可視化します。W&B ダッシュボードは、機械学習モデルからの結果を整理し可視化する中心的な場所です。これは、W&B にログされていない以前の機械学習実験の情報を含む CSV ファイル やデータセットを含む CSV ファイル がある場合に特に便利です。
データセットの CSV ファイルをインポートしてログする
W&B Artifacts を使用することをお勧めします。CSV ファイルの内容を再利用しやすくするためです。
まず、CSV ファイルをインポートします。以下のコードスニペットでは、iris.csv ファイル名をあなたの CSV ファイル名に置き換えてください:
import wandb
import pandas as pd
# CSV を新しい DataFrame に読み込む
new_iris_dataframe = pd. read_csv("iris.csv" )
CSV ファイルを W&B Table に変換し、W&B ダッシュボード を利用します。
# DataFrame を W&B Table に変換
iris_table = wandb. Table(dataframe= new_iris_dataframe)
次に、W&B Artifact を作成し、テーブルを Artifact に追加します:
# テーブルを Artifact に追加し、行制限を 200,000 に増やし、再利用しやすくする
iris_table_artifact = wandb. Artifact("iris_artifact" , type= "dataset" )
iris_table_artifact. add(iris_table, "iris_table" )
# データを保存するために、生の CSV ファイルを Artifact 内にログする
iris_table_artifact. add_file("iris.csv" )
W&B Artifacts についての詳細は、Artifacts チャプター を参照してください。
最後に、wandb.init を使用して W&B で追跡しログするために新しい W&B Run を開始します:
# データをログするために W&B run を開始
run = wandb. init(project= "tables-walkthrough" )
# テーブルをログして run で可視化
run. log({"iris" : iris_table})
# そして行制限を増やすためにアーティファクトとしてログ!
run. log_artifact(iris_table_artifact)
wandb.init() API は新しいバックグラウンドプロセスを開始し、データを Run にログし、デフォルトで wandb.ai に同期します。W&B ワークスペースダッシュボードでライブの可視化を表示します。以下の画像はコードスニペットのデモの出力を示しています。
以下は、前述のコードスニペットを含む完全なスクリプトです:
import wandb
import pandas as pd
# CSV を新しい DataFrame に読み込む
new_iris_dataframe = pd. read_csv("iris.csv" )
# DataFrame を W&B Table に変換
iris_table = wandb. Table(dataframe= new_iris_dataframe)
# テーブルを Artifact に追加し、行制限を 200,000 に増やし、再利用しやすくする
iris_table_artifact = wandb. Artifact("iris_artifact" , type= "dataset" )
iris_table_artifact. add(iris_table, "iris_table" )
# データを保存するために、生の CSV ファイルを Artifact 内にログする
iris_table_artifact. add_file("iris.csv" )
# データをログするために W&B run を開始
run = wandb. init(project= "tables-walkthrough" )
# テーブルをログして run で可視化
run. log({"iris" : iris_table})
# そして行制限を増やすためにアーティファクトとしてログ!
run. log_artifact(iris_table_artifact)
# run を終了する (ノートブックで便利)
run. finish()
実験の CSV をインポートしてログする
場合によっては、実験の詳細が CSV ファイルにあることがあります。そのような CSV ファイルに共通する詳細には次のようなものがあります:
実験
モデル名
ノート
タグ
層の数
最終トレイン精度
最終評価精度
トレーニング損失
実験 1
mnist-300-layers
トレーニングデータに過剰適合
[latest]
300
0.99
0.90
[0.55, 0.45, 0.44, 0.42, 0.40, 0.39]
実験 2
mnist-250-layers
現行の最良モデル
[prod, best]
250
0.95
0.96
[0.55, 0.45, 0.44, 0.42, 0.40, 0.39]
実験 3
mnist-200-layers
ベースラインモデルより悪かったため、デバッグ必要
[debug]
200
0.76
0.70
[0.55, 0.45, 0.44, 0.42, 0.40, 0.39]
…
…
…
…
…
…
…
実験 N
mnist-X-layers
ノート
…
…
…
…
[…, …]
W&B は実験の CSV ファイルを受け取り、W&B 実験 Run に変換することができます。次のコードスニペットとコードスクリプトで、実験の CSV ファイルをインポートしてログする方法を示しています:
最初に、CSV ファイルを読み込んで Pandas DataFrame に変換します。"experiments.csv" を CSV ファイル名に置き換えてください:
import wandb
import pandas as pd
FILENAME = "experiments.csv"
loaded_experiment_df = pd. read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers" ]
SUMMARY_COLS = ["Final Train Acc" , "Final Val Acc" ]
METRIC_COLS = ["Training Losses" ]
# 作業を容易にするための Pandas DataFrame のフォーマット
for i, row in loaded_experiment_df. iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
次に、wandb.init()
run = wandb. init(
project= PROJECT_NAME, name= run_name, tags= tags, notes= notes, config= config
)
実験が進行するにつれて、メトリクスのすべてのインスタンスをログし、W&B で表示、クエリ、および分析可能にすることをお勧めするかもしれません。これを実現するには、run.log()
また、run の結果を定義するために最終的なサマリーメトリクスをオプションでログすることもできます。これを実現するには、W&B define_metricrun.summary.update() によりサマリーメトリクスを run に追加します:
run. summary. update(summaries)
サマリーメトリクスの詳細については、Log Summary Metrics を参照してください。
以下は、上記のサンプルテーブルを W&B ダッシュボード に変換する完全な例のスクリプトです:
FILENAME = "experiments.csv"
loaded_experiment_df = pd. read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers" ]
SUMMARY_COLS = ["Final Train Acc" , "Final Val Acc" ]
METRIC_COLS = ["Training Losses" ]
for i, row in loaded_experiment_df. iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
run = wandb. init(
project= PROJECT_NAME, name= run_name, tags= tags, notes= notes, config= config
)
for key, val in metrics. items():
if isinstance(val, list):
for _val in val:
run. log({key: _val})
else :
run. log({key: val})
run. summary. update(summaries)
run. finish()
8 - 分散トレーニング実験をログする
W&B を使用して、複数の GPU を用いた分散トレーニング実験をログする。
分散トレーニングでは、複数の GPU を使ってモデルが並列にトレーニングされます。W&B は、分散トレーニング実験をトラッキングするための2つのパターンをサポートしています。
ワンプロセス : 単一のプロセスから W&B を初期化し(wandb.initwandb.logPyTorch Distributed Data Parallel (DDP)クラスを使った分散トレーニング実験のログに一般的なソリューションです。ユーザーは他のプロセスからメインのロギングプロセスにデータを送るために、多重処理キュー(または他の通信プリミティブ)を使用することもあります。多数のプロセス : 各プロセスで W&B を初期化し(wandb.initwandb.loggroup パラメータを使用して共有実験を定義し、W&B App UI のログした値を一緒にグループ化します。
次に示す例は、PyTorch DDP を使って単一のマシン上で2つの GPU でメトリクスを W&B でトラッキングする方法を示しています。PyTorch DDP (torch.nn の DistributedDataParallel)は、分散トレーニングのための人気のあるライブラリです。基本的な原則はどの分散トレーニングセットアップにも適用されますが、実装の詳細は異なる場合があります。
方法 1: ワンプロセス
この方法では、ランク 0 のプロセスのみをトラッキングします。この方法を実装するには、ランク 0 のプロセス内で W&B を初期化し(wandb.init)、W&B Run を開始し、メトリクスをログ(wandb.log)します。この方法はシンプルで堅牢ですが、他のプロセスからモデルメトリクス(例えば、ロス値や各バッチからの入力)をログしません。使用状況やメモリなどのシステムメトリクスは、すべての GPU に利用可能な情報であるため、引き続きログされます。
単一のプロセスで利用可能なメトリクスのみをトラッキングする場合、この方法を使用してください。 典型的な例には、GPU/CPU 使用率、共有 validation set 上の挙動、勾配とパラメータ、代表的なデータ例上の損失値が含まれます。
サンプル Python スクリプト (log-ddp.py) では、ランクが 0 かどうかを確認します。そのためには、まず torch.distributed.launch を使って複数のプロセスを開始します。次に、--local_rank コマンドライン引数を使用してランクを確認します。ランクが 0 に設定されている場合、train()wandb ロギングを設定します。Python スクリプト内では、次のように確認します。
if __name__ == "__main__" :
# 引数を取得
args = parse_args()
if args. local_rank == 0 : # メインプロセスでのみ
# wandb run を初期化
run = wandb. init(
entity= args. entity,
project= args. project,
)
# DDP でモデルをトレーニング
train(args, run)
else :
train(args)
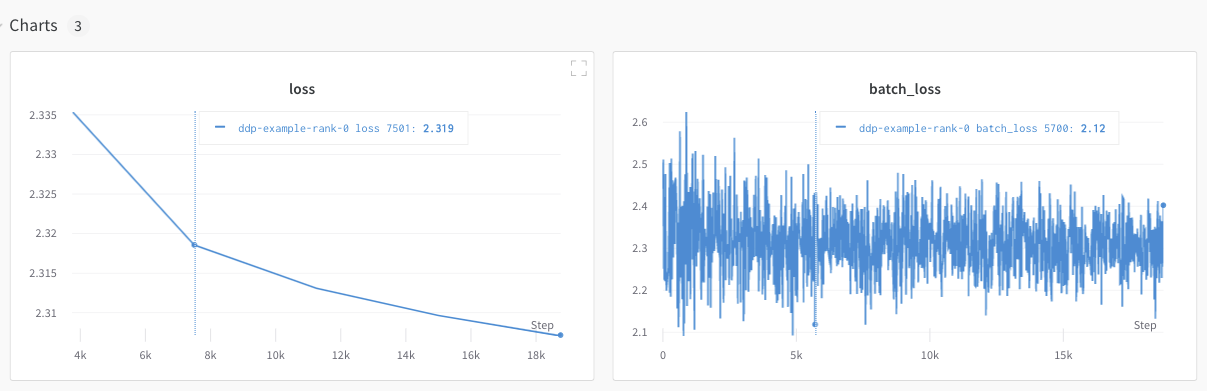
W&B App UI を探索して、単一プロセスからトラッキングされたメトリクスの ダッシュボードの例 をご覧ください。ダッシュボードは、両方の GPU に対してトラッキングされた温度や使用率などのシステムメトリクスを表示します。
しかし、エポックとバッチサイズの関数としてのロス値は、単一の GPU からのみログされました。
方法 2: 多数のプロセス
この方法では、ジョブ内の各プロセスをトラッキングし、各プロセスから個別に wandb.init() と wandb.log() を呼び出します。トレーニングの終了時には wandb.finish() を呼び出して、run が完了したことを示し、すべてのプロセスが正常に終了するようにすることをお勧めします。
この方法では、さらに多くの情報がログにアクセス可能になりますが、W&B App UI に複数の W&B Runs が報告されます。複数の実験にわたって W&B Runs を追跡するのが困難になる可能性があります。これを軽減するために、W&B を初期化する際に group パラメータに値を与えて、どの W&B Run がどの実験に属しているかを追跡します。実験でのトレーニングと評価の W&B Runs の追跡方法の詳細については、Group Runs を参照してください。
個々のプロセスからメトリクスをトラッキングしたい場合はこの方法を使用してください。 典型的な例には、各ノードでのデータと予測(データ分散のデバッグ用)やメインノードの外側での個々のバッチのメトリクスが含まれます。この方法は、すべてのノードからのシステムメトリクスやメインノードで利用可能な要約統計データを取得するために必要ありません。
以下の Python コードスニペットは、W&B を初期化する際に group パラメータを設定する方法を示しています。
if __name__ == "__main__" :
# 引数を取得
args = parse_args()
# run を初期化
run = wandb. init(
entity= args. entity,
project= args. project,
group= "DDP" , # 実験のすべての run を1つのグループに
)
# DDP でモデルをトレーニング
train(args, run)
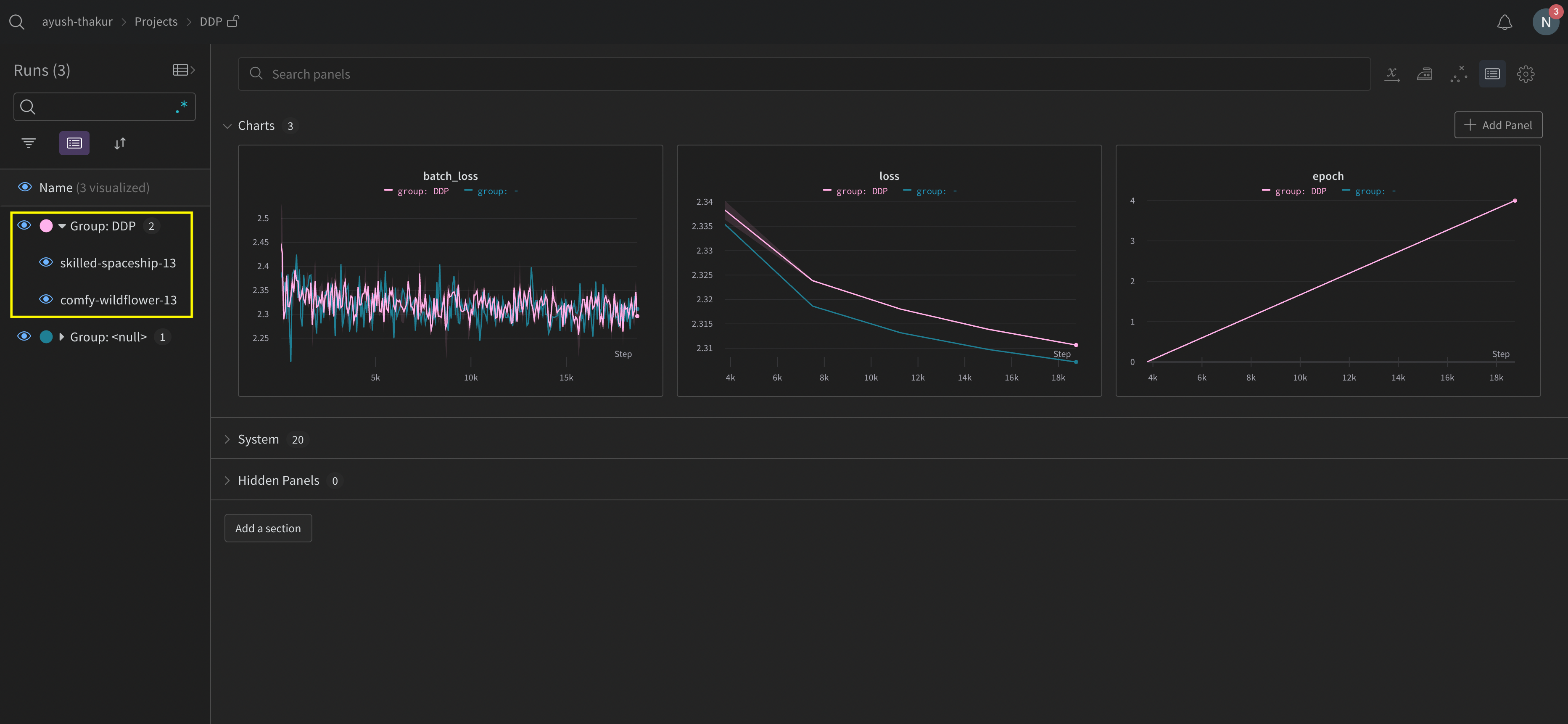
W&B App UI を探索して、複数のプロセスからトラッキングされたメトリクスの ダッシュボードの例 をご覧ください。左側のサイドバーに 2 つの W&B Runs が組み合わされたものが示されています。グループをクリックして、その実験専用のグループページを表示します。専用のグループページには、各プロセスから別々にログされたメトリクスが表示されます。
前の画像は W&B App UI ダッシュボードを示しています。サイドバーには2つの実験が表示されています。1つは「null」とラベル付けされ、黄色のボックスで囲まれた2つ目は「DPP」と呼ばれます。グループを展開すると([Group] ドロップダウンを選択)、その実験に関連する W&B Runs を見ることができます。
共通の分散トレーニングの問題を避けるために W&B Service を使用
W&B と分散トレーニングを使用する場合、2つの一般的な問題に遭遇することがあります。
トレーニングの開始時のハング - wandb プロセスが、分散トレーニングからの多重処理と干渉するためにハングすることがあります。トレーニングの終了時のハング - トレーニングジョブが、wandb プロセスがいつ終了する必要があるかを知らない場合、ハングすることがあります。Python スクリプトの最後に wandb.finish() API を呼び出して、W&B に Run が終了したことを通知します。wandb.finish() API はデータのアップロードを完了し、W&B の終了を引き起こします。
wandb service を使用して、分散ジョブの信頼性を向上させることをお勧めします。上記のトレーニングの問題は、wandb service が利用できない W&B SDK のバージョンで一般的に見られます。
W&B Service の有効化
お使いのバージョンの W&B SDK に応じて、すでにデフォルトで W&B Service が有効になっているかもしれません。
W&B SDK 0.13.0 以上
W&B SDK バージョン 0.13.0 以上のバージョンでは、W&B Service がデフォルトで有効です。
W&B SDK 0.12.5 以上
W&B SDK バージョン 0.12.5 以上の場合は、Python スクリプトを修正して W&B Service を有効にします。wandb.require メソッドを使用し、メイン関数内で文字列 "service" を渡します。
if __name__ == "__main__" :
main()
def main ():
wandb. require("service" )
# スクリプトの残りがここに来る
最適な体験のために、最新バージョンへのアップグレードをお勧めします。
W&B SDK 0.12.4 以下
W&B SDK バージョン 0.12.4 以下を使用する場合は、マルチスレッドを代わりに使用するために、WANDB_START_METHOD 環境変数を "thread" に設定します。
マルチプロセスの例々
以下のコードスニペットは、高度な分散ユースケースの一般的なメソッドを示しています。
プロセスの生成
ワークスレッドを生成するプロセス内で W&B Run を開始する場合は、メイン関数で wandb.setup() メソッドを使用します。
import multiprocessing as mp
def do_work (n):
run = wandb. init(config= dict(n= n))
run. log(dict(this= n * n))
def main ():
wandb. setup()
pool = mp. Pool(processes= 4 )
pool. map(do_work, range(4 ))
if __name__ == "__main__" :
main()
W&B Run の共有
W&B Run オブジェクトを引数として渡して、プロセス間で W&B Runs を共有します。
def do_work (run):
run. log(dict(this= 1 ))
def main ():
run = wandb. init()
p = mp. Process(target= do_work, kwargs= dict(run= run))
p. start()
p. join()
if __name__ == "__main__" :
main()
記録の順序は保証できないことに注意してください。同期はスクリプトの作成者が行う必要があります。