スイープ
W&B スイープによるハイパーパラメーター探索とモデル最適化
W&B Sweeps を使用してハイパーパラメータ検索を自動化し、豊富でインタラクティブな実験管理を視覚化します。ベイズ、グリッド検索、ランダムなどの一般的な検索メソッドから選択して、ハイパーパラメータ空間を探索できます。スイープを 1 台以上のマシンにわたってスケールし、並列化します。
仕組み
2 つの W&B CLI コマンドで sweep を作成します:
スイープを初期化する
wandb sweep --project <propject-name> <path-to-config file>
スイープエージェントを開始する
上記のコードスニペットとこのページにリンクされている colab は、W&B CLI でスイープを初期化し作成する方法を示しています。W&B Python SDK コマンドを使用してスイープ設定を定義し、スイープを初期化・開始する手順については Sweeps の
ウォークスルー をご覧ください。
開始方法
ユースケースに応じて、W&B Sweeps の開始に役立つ次のリソースを探索してください:
スイープ設定を定義し、スイープを初期化・開始するための W&B Python SDK コマンドの手順については、スイープのウォークスルー をお読みください。
次のチャプターを探索して以下を学びます:
W&B Sweeps を使用したハイパーパラメータ最適化を探索する スイープ実験の厳選リスト を探索します。結果は W&B Reports に保存されます。
ステップバイステップのビデオについては、こちらをご覧ください: Tune Hyperparameters Easily with W&B Sweeps .
1 - チュートリアル: Sweep を定義、初期化、実行する
スイープ クイックスタートでは、スイープを定義、初期化、実行する方法を示します。主な手順は4つあります。
このページでは、スイープを定義、初期化、および実行する方法を示します。主に4つのステップがあります。
トレーニングコードをセットアップする スイープ設定で探索空間を定義する スイープを初期化する スイープエージェントを開始する
以下のコードを Jupyter ノートブックまたは Python スクリプトにコピーして貼り付けてください。
# W&B Python ライブラリをインポートして W&B にログインする
import wandb
wandb. login()
# 1: 目的/トレーニング関数を定義する
def objective (config):
score = config. x** 3 + config. y
return score
def main ():
wandb. init(project= "my-first-sweep" )
score = objective(wandb. config)
wandb. log({"score" : score})
# 2: 探索空間を定義する
sweep_configuration = {
"method" : "random" ,
"metric" : {"goal" : "minimize" , "name" : "score" },
"parameters" : {
"x" : {"max" : 0.1 , "min" : 0.01 },
"y" : {"values" : [1 , 3 , 7 ]},
},
}
# 3: スイープを開始する
sweep_id = wandb. sweep(sweep= sweep_configuration, project= "my-first-sweep" )
wandb. agent(sweep_id, function= main, count= 10 )
以下のセクションでは、そのコードサンプルの各ステップを分解し、説明します。
トレーニングコードをセットアップする
wandb.config からハイパーパラメーターの値を取り込み、それを使用してモデルをトレーニングし、メトリクスを返すトレーニング関数を定義します。
オプションとして、W&B Run の出力を保存したいプロジェクトの名前(wandb.init
スイープとrunは同じプロジェクト内にある必要があります。したがって、W&Bを初期化するときに指定する名前は、スイープを初期化するときに指定するプロジェクトの名前と一致する必要があります。
# 1: 目的/トレーニング関数を定義する
def objective (config):
score = config. x** 3 + config. y
return score
def main ():
wandb. init(project= "my-first-sweep" )
score = objective(wandb. config)
wandb. log({"score" : score})
スイープ設定で探索空間を定義する
探索するハイパーパラメーターを辞書で指定します。設定オプションについては、スイープ設定を定義する を参照してください。
次の例では、ランダム検索('method':'random')を使用するスイープ設定を示しています。スイープは、バッチサイズ、エポック、および学習率の設定にリストされているランダムな値を無作為に選択します。
W&Bは、"goal": "minimize"が関連付けられているときに metric キーで指定されたメトリクスを最小化します。この場合、W&Bはメトリクス score("name": "score")を最小化するように最適化します。
# 2: 探索空間を定義する
sweep_configuration = {
"method" : "random" ,
"metric" : {"goal" : "minimize" , "name" : "score" },
"parameters" : {
"x" : {"max" : 0.1 , "min" : 0.01 },
"y" : {"values" : [1 , 3 , 7 ]},
},
}
スイープを初期化する
W&Bは、クラウド(標準)またはローカル(ローカル)で複数のマシンを横断してスイープを管理するために、Sweep Controller を使用します。Sweep Controller についての詳細は、ローカルで探索と停止のアルゴリズムを確認する を参照してください。
スイープを初期化すると、スイープ識別番号が返されます。
sweep_id = wandb. sweep(sweep= sweep_configuration, project= "my-first-sweep" )
スイープの初期化に関する詳細は、スイープを初期化する を参照してください。
スイープを開始する
スイープを開始するには、wandb.agent
wandb. agent(sweep_id, function= main, count= 10 )
結果を視覚化する(オプション)
プロジェクトを開くと、W&Bアプリダッシュボードでライブ結果を確認できます。数回のクリックで豊富なインタラクティブグラフを構築します。例えば、並列座標プロット 、パラメータの重要度解析 、およびその他 です。
結果の視覚化方法に関する詳細は、スイープ結果を視覚化する を参照してください。サンプルのダッシュボードについては、このスイーププロジェクト を参照してください。
エージェントを停止する(オプション)
ターミナルで Ctrl+C を押して、現在のランを停止します。もう一度押すと、エージェントが終了します。
2 - コードに W&B (wandb) を追加する
Python コード スクリプトまたは Jupyter Notebook に W&B を追加します。
W&B Python SDKをスクリプトやJupyterノートブックに追加する方法は数多くあります。以下は、W&B Python SDKを独自のコードに統合するための「ベストプラクティス」の例です。
オリジナルトレーニングスクリプト
次のPythonスクリプトのコードを持っているとしましょう。main という関数を定義し、典型的なトレーニングループを模倣します。各エポックごとに、トレーニングおよび検証データセットに対して精度と損失が計算されます。この例の目的のために値はランダムに生成されます。
ハイパーパラメーター値を格納するための辞書 config を定義しました。セルの最後に、モックトレーニングコードを実行するために main 関数を呼び出します。
import random
import numpy as np
def train_one_epoch (epoch, lr, bs):
acc = 0.25 + ((epoch / 30 ) + (random. random() / 10 ))
loss = 0.2 + (1 - ((epoch - 1 ) / 10 + random. random() / 5 ))
return acc, loss
def evaluate_one_epoch (epoch):
acc = 0.1 + ((epoch / 20 ) + (random. random() / 10 ))
loss = 0.25 + (1 - ((epoch - 1 ) / 10 + random. random() / 6 ))
return acc, loss
# ハイパーパラメーター値を含む設定変数
config = {"lr" : 0.0001 , "bs" : 16 , "epochs" : 5 }
def main ():
# 固定値を定義する代わりに `wandb.config` から値を定義していることに注意
lr = config["lr" ]
bs = config["bs" ]
epochs = config["epochs" ]
for epoch in np. arange(1 , epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
print("epoch: " , epoch)
print("training accuracy:" , train_acc, "training loss:" , train_loss)
print("validation accuracy:" , val_acc, "training loss:" , val_loss)
W&B Python SDKを用いたトレーニングスクリプト
以下のコード例は、W&B Python SDKをコードに追加する方法を示しています。CLIでW&B Sweepジョブを開始する場合、CLIタブを探索したいでしょう。JupyterノートブックやPythonスクリプト内でW&B Sweepジョブを開始する場合、Python SDKタブを探索してください。
Python スクリプトまたはノートブック
CLI
W&B Sweepを作成するために、コード例に以下を追加しました:
Weights & Biases Python SDKをインポートします。
キーと値のペアがスイープ設定を定義する辞書オブジェクトを作成します。次の例では、バッチサイズ (batch_size), エポック (epochs), および学習率 (lr) のハイパーパラメーターが各スイープで変化します。スイープ設定の作成方法についての詳細は、Define sweep configuration を参照してください。
スイープ設定辞書をwandb.sweepsweep_id) が返されます。スイープの初期化方法についての詳細は、Initialize sweeps を参照してください。
wandb.init()W&B Run として実行します。(オプション) 固定値を定義する代わりに wandb.config から値を定義します。
wandb.log を使用して最適化したいメトリクスをログします。設定で定義されたメトリクスを必ずログしてください。この例では、設定辞書 (sweep_configuration) で val_acc を最大化するスイープを定義しました。wandb.agentfunction=main)、および試行する最大run数を4に設定します (count=4)。W&B Sweepの開始方法についての詳細は、Start sweep agents を参照してください。
import wandb
import numpy as np
import random
# スイープ設定を定義
sweep_configuration = {
"method" : "random" ,
"name" : "sweep" ,
"metric" : {"goal" : "maximize" , "name" : "val_acc" },
"parameters" : {
"batch_size" : {"values" : [16 , 32 , 64 ]},
"epochs" : {"values" : [5 , 10 , 15 ]},
"lr" : {"max" : 0.1 , "min" : 0.0001 },
},
}
# 設定を渡してスイープを初期化します。
# (オプション) プロジェクト名を指定
sweep_id = wandb. sweep(sweep= sweep_configuration, project= "my-first-sweep" )
# `wandb.config` からハイパーパラメーターを受け取り、
# モデルをトレーニングしてメトリクスを返すトレーニング関数を定義
def train_one_epoch (epoch, lr, bs):
acc = 0.25 + ((epoch / 30 ) + (random. random() / 10 ))
loss = 0.2 + (1 - ((epoch - 1 ) / 10 + random. random() / 5 ))
return acc, loss
def evaluate_one_epoch (epoch):
acc = 0.1 + ((epoch / 20 ) + (random. random() / 10 ))
loss = 0.25 + (1 - ((epoch - 1 ) / 10 + random. random() / 6 ))
return acc, loss
def main ():
run = wandb. init()
# 固定値を定義する代わりに `wandb.config`
# から値を定義していることに注意
lr = wandb. config. lr
bs = wandb. config. batch_size
epochs = wandb. config. epochs
for epoch in np. arange(1 , epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
wandb. log(
{
"epoch" : epoch,
"train_acc" : train_acc,
"train_loss" : train_loss,
"val_acc" : val_acc,
"val_loss" : val_loss,
}
)
# スイープジョブを開始
wandb. agent(sweep_id, function= main, count= 4 )
W&B Sweepを作成するために、最初にYAML設定ファイルを作成します。設定ファイルにはスイープが探索するハイパーパラメーターを含んでいます。次の例では、バッチサイズ (batch_size), エポック (epochs), および学習率 (lr) のハイパーパラメーターが各スイープで変化します。
# config.yaml
program : train.py
method : random
name : sweep
metric :
goal : maximize
name : val_acc
parameters :
batch_size :
values : [16 ,32 ,64 ]
lr :
min : 0.0001
max : 0.1
epochs :
values : [5 , 10 , 15 ]
W&B Sweep設定の作成方法についての詳細は、Define sweep configuration を参照してください。
YAMLファイルで program のキーにPythonスクリプトの名前を必ず指定してください。
次に、コード例に以下を追加します:
Weights & Biases Python SDK (wandb) と PyYAML (yaml) をインポートします。PyYAMLはYAML設定ファイルを読み込むために使用します。
設定ファイルを読み込みます。
wandb.init()W&B Run として実行します。configパラメーターに設定オブジェクトを渡します。固定値を使用する代わりに wandb.config からハイパーパラメーター値を定義します。
wandb.log を使用して最適化したいメトリクスをログします。設定で定義されたメトリクスを必ずログしてください。この例では、設定辞書 (sweep_configuration) で val_acc を最大化するスイープを定義しました。
import wandb
import yaml
import random
import numpy as np
def train_one_epoch (epoch, lr, bs):
acc = 0.25 + ((epoch / 30 ) + (random. random() / 10 ))
loss = 0.2 + (1 - ((epoch - 1 ) / 10 + random. random() / 5 ))
return acc, loss
def evaluate_one_epoch (epoch):
acc = 0.1 + ((epoch / 20 ) + (random. random() / 10 ))
loss = 0.25 + (1 - ((epoch - 1 ) / 10 + random. random() / 6 ))
return acc, loss
def main ():
# 標準のハイパーパラメーターをセットアップします
with open("./config.yaml" ) as file:
config = yaml. load(file, Loader= yaml. FullLoader)
run = wandb. init(config= config)
# 固定値を定義する代わりに `wandb.config`
# から値を定義していることに注意
lr = wandb. config. lr
bs = wandb. config. batch_size
epochs = wandb. config. epochs
for epoch in np. arange(1 , epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
wandb. log(
{
"epoch" : epoch,
"train_acc" : train_acc,
"train_loss" : train_loss,
"val_acc" : val_acc,
"val_loss" : val_loss,
}
)
# メイン関数を呼び出します。
main()
CLIに移動します。CLI内で、スイープエージェントが試行する最大run数を設定します。これは任意のステップです。次の例では最大回数を5に設定しています。
次に、wandb sweep--project)のためにプロジェクト名を指定することもできます:
wandb sweep --project sweep-demo-cli config.yaml
これによりスイープIDが返されます。スイープの初期化方法についての詳細は、Initialize sweeps を参照してください。
スイープIDをコピーし、次のコードスニペットの sweepID を置き換えて、wandb agent
wandb agent --count $NUM your-entity/sweep-demo-cli/sweepID
スイープジョブの開始方法についての詳細は、Start sweep jobs を参照してください。
メトリクスをログする際の考慮事項
スイープ設定で指定したメトリクスを明示的にW&Bにログすることを確認してください。スイープのメトリクスをサブディレクトリ内でログしないでください。
例えば、以下の擬似コードを考えてみてください。ユーザーが検証損失 ("val_loss": loss) をログしたいとします。まず、ユーザーは辞書に値を渡しますが、wandb.log に渡される辞書は辞書内のキーと値のペアに明示的にアクセスしていません:
# W&B Pythonライブラリをインポートし、W&Bにログイン
import wandb
import random
def train ():
offset = random. random() / 5
acc = 1 - 2 **- epoch - random. random() / epoch - offset
loss = 2 **- epoch + random. random() / epoch + offset
val_metrics = {"val_loss" : loss, "val_acc" : acc}
return val_metrics
def main ():
wandb. init(entity= "<entity>" , project= "my-first-sweep" )
val_metrics = train()
# 不正確。辞書内のキーと値のペアに明示的にアクセスする必要があります。
# 次のコードブロックでメトリクスを正しくログする方法を参照してください。
wandb. log({"val_loss" : val_metrics})
sweep_configuration = {
"method" : "random" ,
"metric" : {"goal" : "minimize" , "name" : "val_loss" },
"parameters" : {
"x" : {"max" : 0.1 , "min" : 0.01 },
"y" : {"values" : [1 , 3 , 7 ]},
},
}
sweep_id = wandb. sweep(sweep= sweep_configuration, project= "my-first-sweep" )
wandb. agent(sweep_id, function= main, count= 10 )
代わりに、Python辞書内でキーと値のペアに明示的にアクセスしてください。例えば、次のコードは wandb.log メソッドに辞書を渡す際にキーと値のペアを指定しています:
# W&B Pythonライブラリをインポートし、W&Bにログイン
import wandb
import random
def train ():
offset = random. random() / 5
acc = 1 - 2 **- epoch - random. random() / epoch - offset
loss = 2 **- epoch + random. random() / epoch + offset
val_metrics = {"val_loss" : loss, "val_acc" : acc}
return val_metrics
def main ():
wandb. init(entity= "<entity>" , project= "my-first-sweep" )
val_metrics = train()
wandb. log({"val_loss" , val_metrics["val_loss" ]})
sweep_configuration = {
"method" : "random" ,
"metric" : {"goal" : "minimize" , "name" : "val_loss" },
"parameters" : {
"x" : {"max" : 0.1 , "min" : 0.01 },
"y" : {"values" : [1 , 3 , 7 ]},
},
}
sweep_id = wandb. sweep(sweep= sweep_configuration, project= "my-first-sweep" )
wandb. agent(sweep_id, function= main, count= 10 )
3 - sweep configuration を定義する
スイープの設定ファイルを作成する方法を学びましょう。
A W&B Sweep は、ハイパーパラメータの値を探索するための戦略と、それを評価するコードを組み合わせたものです。この戦略はすべてのオプションを試すというシンプルなものから、ベイズ最適化やハイパーバンド(BOHB )のように複雑なものまであります。
Sweep configuration を Python 辞書 または YAML ファイルで定義します。Sweep configuration をどのように定義するかは、あなたが sweep をどのように管理したいかによって異なります。
スイープを初期化し、コマンドラインからスイープエージェントを開始したい場合は、YAMLファイルでスイープ設定を定義します。スイープを初期化し、完全にPythonスクリプトまたはJupyterノートブック内でスイープを開始する場合は、Python辞書でスイープを定義します。
以下のガイドでは、sweep configuration のフォーマット方法について説明します。Sweep configuration options で、トップレベルの sweep configuration キーの包括的なリストをご覧ください。
基本構造
両方のスイープ設定フォーマットオプション (YAML および Python 辞書) は、キーと値のペアおよびネストされた構造を利用します。
スイープ設定内でトップレベルキーを使用して、sweep 検索の特性を定義します。たとえば、スイープの名前(nameparametersmethod
例えば、以下のコードスニペットは、YAML ファイルと Python 辞書の両方で定義された同じスイープ設定を示しています。スイープ設定内には、program、name、method、metric、および parameters という5つのトップレベルキーが指定されています。
CLI
Python スクリプトまたは Jupyter ノートブック
スイープをコマンドライン (CLI) からインタラクティブに管理したい場合、YAML ファイルでスイープ設定を定義します。
program : train.py
name : sweepdemo
method : bayes
metric :
goal : minimize
name : validation_loss
parameters :
learning_rate :
min : 0.0001
max : 0.1
batch_size :
values : [16 , 32 , 64 ]
epochs :
values : [5 , 10 , 15 ]
optimizer :
values : ["adam" , "sgd" ]
Python スクリプトまたは Jupyter ノートブックでトレーニングアルゴリズムを定義する場合は、Python 辞書データ構造でスイープを定義します。
以下のコードスニペットは、sweep_configuration という変数名でスイープ設定を格納します:
sweep_configuration = {
"name" : "sweepdemo" ,
"method" : "bayes" ,
"metric" : {"goal" : "minimize" , "name" : "validation_loss" },
"parameters" : {
"learning_rate" : {"min" : 0.0001 , "max" : 0.1 },
"batch_size" : {"values" : [16 , 32 , 64 ]},
"epochs" : {"values" : [5 , 10 , 15 ]},
"optimizer" : {"values" : ["adam" , "sgd" ]},
},
}
トップレベルの parameters キーの中に、以下のキーがネストされています:learning_rate、batch_size、epoch、および optimizer。指定したネストされたキーごとに、1つ以上の値、分布、確率などを提供できます。詳細については、Sweep configuration options の parameters セクションを参照してください。
二重ネストパラメータ
Sweep configurations はネストされたパラメータをサポートします。ネストされたパラメータを区切るには、トップレベルのパラメータ名の下に追加の parameters キーを使用します。スイープ設定は多層ネストをサポートします。
ベイズまたはランダムなハイパーパラメータ検索を使用する場合、確率分布を指定します。各ハイパーパラメータについて:
スイープ設定でトップレベル parameters キーを作成します。
parameters キーの中に次のものをネストします:
最適化したいハイパーパラメータの名前を指定します。
distribution キーのために使用したい分布を指定します。ハイパーパラメータ名の下に distribution キーと値のペアをネストします。探索する1つ以上の値を指定します。その値(または値のリスト)は分布キーと整合している必要があります。
(オプション) トップレベルのパラメータ名の下に追加のパラメータキーを使用して、ネストされたパラメータを区切ります。
スイープ設定で定義されたネストされたパラメータは、W&B run 設定で指定されたキーを上書きします。
例として、次の設定で train.py Python スクリプト(行1-2で確認可能)で W&B run を初期化するとします。次に、sweep_configuration(行4-13)の辞書でスイープ設定を定義します。その後、スイープ設定辞書を wandb.sweep に渡してスイープ設定を初期化します(行16を確認)。
def main ():
run = wandb. init(config= {"nested_param" : {"manual_key" : 1 }})
sweep_configuration = {
"top_level_param" : 0 ,
"nested_param" : {
"learning_rate" : 0.01 ,
"double_nested_param" : {"x" : 0.9 , "y" : 0.8 },
},
}
# Initialize sweep by passing in config.
sweep_id = wandb. sweep(sweep= sweep_configuration, project= "<project>" )
# Start sweep job.
wandb. agent(sweep_id, function= main, count= 4 )
W&B run が初期化されたときに渡された nested_param.manual_key はアクセスできません。run.config は、スイープ設定辞書で定義されたキーと値のペアのみを持っています。
Sweep configuration テンプレート
次のテンプレートには、パラメータを構成し、検索制約を指定する方法を示しています。hyperparameter_name をあなたのハイパーパラメータの名前と、<> 内の任意の値で置き換えます。
program : <insert>
method : <insert>
parameter :
hyperparameter_name0 :
value : 0
hyperparameter_name1 :
values : [0 , 0 , 0 ]
hyperparameter_name :
distribution : <insert>
value : <insert>
hyperparameter_name2 :
distribution : <insert>
min : <insert>
max : <insert>
q : <insert>
hyperparameter_name3 :
distribution : <insert>
values :
- <list_of_values>
- <list_of_values>
- <list_of_values>
early_terminate :
type : hyperband
s : 0
eta : 0
max_iter : 0
command :
- ${Command macro}
- ${Command macro}
- ${Command macro}
- ${Command macro}
Sweep configuration の例
CLI
Python スクリプトまたは Jupyter ノートブック
program : train.py
method : random
metric :
goal : minimize
name : loss
parameters :
batch_size :
distribution : q_log_uniform_values
max : 256
min : 32
q : 8
dropout :
values : [0.3 , 0.4 , 0.5 ]
epochs :
value : 1
fc_layer_size :
values : [128 , 256 , 512 ]
learning_rate :
distribution : uniform
max : 0.1
min : 0
optimizer :
values : ["adam" , "sgd" ]
sweep_config = {
"method" : "random" ,
"metric" : {"goal" : "minimize" , "name" : "loss" },
"parameters" : {
"batch_size" : {
"distribution" : "q_log_uniform_values" ,
"max" : 256 ,
"min" : 32 ,
"q" : 8 ,
},
"dropout" : {"values" : [0.3 , 0.4 , 0.5 ]},
"epochs" : {"value" : 1 },
"fc_layer_size" : {"values" : [128 , 256 , 512 ]},
"learning_rate" : {"distribution" : "uniform" , "max" : 0.1 , "min" : 0 },
"optimizer" : {"values" : ["adam" , "sgd" ]},
},
}
ベイズハイパーバンドの例
program : train.py
method : bayes
metric :
goal : minimize
name : val_loss
parameters :
dropout :
values : [0.15 , 0.2 , 0.25 , 0.3 , 0.4 ]
hidden_layer_size :
values : [96 , 128 , 148 ]
layer_1_size :
values : [10 , 12 , 14 , 16 , 18 , 20 ]
layer_2_size :
values : [24 , 28 , 32 , 36 , 40 , 44 ]
learn_rate :
values : [0.001 , 0.01 , 0.003 ]
decay :
values : [1e-5 , 1e-6 , 1e-7 ]
momentum :
values : [0.8 , 0.9 , 0.95 ]
epochs :
value : 27
early_terminate :
type : hyperband
s : 2
eta : 3
max_iter : 27
以下のタブで early_terminate の最小または最大のイテレーション回数を指定する方法を示します:
最大のイテレーション回数
最小のイテレーション回数
この例のブラケットは [3, 3*eta, 3*eta*eta, 3*eta*eta*eta] で、結果として [3, 9, 27, 81] になります。
early_terminate :
type : hyperband
min_iter : 3
この例のブラケットは [27/eta, 27/eta/eta] で、[9, 3] になります。
early_terminate :
type : hyperband
max_iter : 27
s : 2
コマンドの例
program : main.py
metric :
name : val_loss
goal : minimize
method : bayes
parameters :
optimizer.config.learning_rate :
min : !!float 1e-5
max : 0.1
experiment :
values : [expt001, expt002]
optimizer :
values : [sgd, adagrad, adam]
command :
- ${env}
- ${interpreter}
- ${program}
- ${args_no_hyphens}
/usr/bin/env python train.py --param1= value1 --param2= value2
python train.py --param1= value1 --param2= value2
以下のタブで一般的なコマンドマクロを指定する方法を示します:
Python インタープリタの設定
追加のパラメータを追加
引数を省略
Hydra
{$interpreter} マクロを削除し、値を明示的に提供して Python インタプリタをハードコードします。例えば、以下のコードスニペットはその方法を示しています:
command :
- ${env}
- python3
- ${program}
- ${args}
次の例では、sweep configuration のパラメータで指定されていないコマンドライン引数を追加する方法を示します:
command :
- ${env}
- ${interpreter}
- ${program}
- "--config"
- "your-training-config.json"
- ${args}
あなたのプログラムが引数パースを使用しない場合、すべての引数を渡すのを避け、wandb.init がスイープパラメータを自動的に wandb.config に取り込むことを利用できます:
command :
- ${env}
- ${interpreter}
- ${program}
ツールのように引数を渡すコマンドを変更できます Hydra が期待する方法です。詳細については、Hydra with W&B を参照してください。
command :
- ${env}
- ${interpreter}
- ${program}
- ${args_no_hyphens}
3.1 - Sweep configuration オプション
スイープ設定は、ネストされたキーと値のペアで構成されます。スイープ設定内のトップレベルのキーを使用して、スイープ検索の特性を定義します。例えば、検索するパラメータ(parametermethod
以下のテーブルはトップレベルのスイープ設定キーとその簡単な説明を示しています。各キーについての詳細情報は、該当するセクションを参照してください。
トップレベルキー
説明
program(必須)実行するトレーニングスクリプト
entityこのスイープのエンティティ
projectこのスイープのプロジェクト
descriptionスイープのテキスト説明
nameW&B UIに表示されるスイープの名前。
method(必須)検索戦略
metric最適化するメトリック(特定の検索戦略と停止基準でのみ使用)
parameters(必須)検索するパラメータの範囲
early_terminate任意の早期停止基準
commandトレーニングスクリプトに引数を渡して呼び出すためのコマンド構造
run_capこのスイープの最大 run 数
スイープ設定の構造については、スイープ設定 の構造を参照してください。
metricmetric トップレベルスイープ設定キーを使用して、最適化するメトリックの名前、目標、そして対象のメトリックを指定します。
キー
説明
name最適化するメトリックの名前。
goalminimize または maximize のいずれか(デフォルトは minimize)。
target最適化するメトリックの目標値。このスイープは、指定した目標値に run が到達した場合や到達する場合、新しい run を作成しません。アクティブなエージェントが run を実行中の場合(runがターゲットに到達した場合)、エージェントが新しい run を作成するのを停止する前に、run が完了するのを待ちます。
parametersYAML ファイルまたは Python スクリプト内で、parameters をトップレベルキーとして指定します。parameters キーの中に、最適化したいハイパーパラメータの名前を提供します。一般的なハイパーパラメーターには、学習率、バッチサイズ、エポック数、オプティマイザーなどがあります。あなたのスイープ設定で定義された各ハイパーパラメータに対して、1つ以上の検索制約を指定します。
以下のテーブルは、サポートされているハイパーパラメータ検索制約を示しています。ハイパーパラメータとユースケースに基づいて、以下のサーチ制約のいずれかを使用して、スイープエージェントに検索する場所(分布の場合)または何を(value、valuesなど)検索または使用するかを指示します。
検索制約
説明
valuesこのハイパーパラメータのすべての有効な値を指定します。gridと互換性があります。
valueこのハイパーパラメータの単一の有効な値を指定します。gridと互換性があります。
distribution確率 分布 を指定します。この表の後の注記ではデフォルト値に関する情報について説明しています。
probabilitiesrandomを使用する際に、valuesのそれぞれの要素を選択する確率を指定します。
min, max(intまたはfloat)最大値と最小値。intの場合、int_uniform で分布されたハイパーパラメータ用。floatの場合、uniformで分布されたハイパーパラメータ用。
mu( float ) normal または lognormal で分布されたハイパーパラメータの平均パラメータ。
sigma( float ) normal または lognormal で分布されたハイパーパラメータの標準偏差パラメータ。
q( float ) 量子化されたハイパーパラメーターの量子化ステップサイズ。
parametersルートレベルのパラメーター内に他のパラメーターをネストします。
W&B は、distribution が指定されていない場合、以下の条件に基づいて以下の分布を設定します:
categorical:valuesが指定された場合int_uniform:maxとminが整数として指定された場合uniform:maxとminが浮動小数点数として指定された場合constant:valueにセットを提供した場合 methodmethodキーを使用して、ハイパーパラメータ検索戦略を指定します。選択できるハイパーパラメーター検索戦略は、グリッド検索、ランダム検索、およびベイズ探索です。
グリッド検索
ハイパーパラメータのすべての組み合わせを反復します。グリッド検索は、各反復で使用するハイパーパラメータ値のセットに対して無知な決定を下します。グリッド検索は計算的に高コストになる可能性があります。
グリッド検索は、連続的な検索空間内を検索している場合、永遠に実行されます。
ランダム検索
分布に基づいて、各反復でランダムかつ無知なハイパーパラメータ値のセットを選択します。ランダム検索は、コマンドラインやあなたの python スクリプト、または W&B アプリUI でプロセスを停止しない限り、永遠に実行されます。
ランダム(method: random)検索を選択した場合、metricキーで分布空間を指定します。
ベイズ探索
ランダム検索 とグリッド検索 とは対照的に、ベイズモデルを使用して情報に基づく決定を行います。ベイズ最適化は、確率モデルを使用して、代理関数の値をテストする反復プロセスを経て、どの値を使用するかを決定します。ベイズ探索は、少数の連続的なパラメータに対して効果的ですが、スケールがうまくいかないことがあります。ベイズ探索に関する詳細情報は、ベイズ最適化の入門書 を参照してください。
ベイズ探索は、コマンドラインやあなたの python スクリプト、または W&B アプリUI でプロセスを停止しない限り、永遠に実行されます。
ランダムおよびベイズ探索の分布オプション
parameter キー内で、ハイパーパラメーターの名前をネストします。次に、distributionキーを指定し、値の分布を指定します。
以下のテーブルでは、W&B がサポートする分布を示しています。
distributionキーの値説明
constant定数分布。使用する定数値(value)を指定する必要があります。
categoricalカテゴリ分布。このハイパーパラメータのすべての有効な値(values)を指定する必要があります。
int_uniform整数上の離散一様分布。max と min を整数として指定する必要があります。
uniform連続一様分布。max と min を浮動小数点数として指定する必要があります。
q_uniform量子化一様分布。X が一様である場合、round(X / q) * q を返します。q はデフォルトで 1。
log_uniform対数一様分布。exp(min) と exp(max) の間で X を返し、自然対数が min と max の間で一様に分布。
log_uniform_values対数一様分布。min と max の間で X を返し、log(X) が log(min) と log(max) の間で一様に分布。
q_log_uniform量子化対数一様分布。X が log_uniform である場合、round(X / q) * q を返します。q はデフォルトで 1。
q_log_uniform_values量子化対数一様分布。X が log_uniform_values である場合、round(X / q) * q を返します。q はデフォルトで 1。
inv_log_uniform逆対数一様分布。X を返し、log(1/X) が min と max の間で一様に分布。
inv_log_uniform_values逆対数一様分布。X を返し、log(1/X) が log(1/max) と log(1/min) の間で一様に分布。
normal正規分布。返される値は平均 mu(デフォルト 0)と標準偏差 sigma(デフォルト 1)で通常に分布。
q_normal量子化正規分布。X が normal である場合、round(X / q) * q を返します。q はデフォルトで 1。
log_normal対数正規分布。X の自然対数 log(X) が平均 mu(デフォルト 0)と標準偏差 sigma(デフォルト 1)で通常に分布する値 X を返します。
q_log_normal量子化対数正規分布。X が log_normal である場合、round(X / q) * q を返します。q はデフォルトで 1。
early_terminate実行のパフォーマンスが悪い場合に停止させるために早期終了(early_terminate)を使用します。早期終了が発生した場合、W&B は現在の run を停止し、新しいハイパーパラメータの値のセットで新しい run を作成します。
early_terminate を使用する場合、停止アルゴリズムを指定する必要があります。スイープ設定内で early_terminate 内に type キーをネストします。
停止アルゴリズム
Hyperband ハイパーパラメータ最適化は、プログラムが停止すべきか、先に進むべきかを、brackets と呼ばれるあらかじめ設定されたイテレーション数で評価します。
W&B run が bracket に到達したとき、sweep はその run のメトリックを過去に報告されたすべてのメトリック値と比較します。run のメトリック値が高すぎる場合(目標が最小化の場合)、または run のメトリックが低すぎる場合(目標が最大化の場合)、sweep は run を終了します。
ベースの反復数に基づいて bracket が設定されます。bracket の数は、最適化するメトリックをログした回数に対応します。反復はステップ、エポック、またはその中間に対応することができます。ステップカウンタの数値は bracket 計算に使用されません。
bracket スケジュールを作成するには、min_iter または max_iter のいずれかを指定してください。
キー
説明
min_iter最初の bracket の反復を指定
max_iter最大反復数を指定。
sbracket の合計数を指定( max_iter に必要)
etabracket 倍数スケジュールを指定(デフォルト: 3)。
strictより厳格にオリジナルの Hyperband 論文に従って run を厳しく削減する「strict」モードを有効にします。デフォルトでは false。
Hyperband は数分ごとに終了する
W&B run を確認します。終了時刻は、run やイテレーションが短い場合、指定された bracket とは異なることがあります。
commandcommand キー内のネストされた値を使用して、形式と内容を修正できます。ファイル名などの固定コンポーネントを直接含めることができます。
Unix システムでは、/usr/bin/env は環境に基づいて OS が正しい Python インタープリターを選択することを保証します。
W&B は、コマンドの可変コンポーネントのために次のマクロをサポートしています:
コマンドマクロ
説明
${env}Unix システムでは /usr/bin/env、Windows では省略されます。
${interpreter}python に展開されます。
${program}スイープ設定 program キーで指定されたトレーニングスクリプトファイル名。
${args}--param1=value1 --param2=value2 の形式でのハイパーパラメーターとその値。
${args_no_boolean_flags}ハイパーパラメータとその値が --param1=value1 の形式であるが、ブールパラメータは True の場合を --boolean_flag_param の形にし、False の場合は省略します。
${args_no_hyphens}param1=value1 param2=value2 の形式でのハイパーパラメータとその値。
${args_json}JSON としてエンコードされたハイパーパラメーターとその値。
${args_json_file}JSON としてエンコードされたハイパーパラメータとその値を含むファイルへのパス。
${envvar}環境変数を渡す方法。${envvar:MYENVVAR} __ は MYENVVAR 環境変数の値に展開されます。 __
4 - sweep を初期化する
W&B で Sweep を初期化する
W&B は、Sweep Controller を使用して、クラウド (標準)、ローカル (ローカル) の 1 台以上のマシンで スイープを管理します。run が完了すると、sweep controller は新しい run を実行するための新しい指示を発行します。これらの指示は、実際に run を実行する agents によって受け取られます。典型的な W&B Sweep では、controller は W&B サーバー上に存在し、agents は_あなたの_マシン上に存在します。
以下のコードスニペットは、CLI、および Jupyter Notebook や Python スクリプト内でスイープを初期化する方法を示しています。
スイープを初期化する前に、スイープ設定が YAML ファイルまたはスクリプト内のネストされた Python 辞書オブジェクトで定義されていることを確認してください。詳細については、sweep configuration を定義する を参照してください。
W&B Sweep と W&B Run は同じ Project 内にある必要があります。そのため、W&B を初期化するときに指定する名前 (wandb.initwandb.sweep
Python script or notebook
CLI
W&B SDK を使用してスイープを初期化します。スイープ設定辞書を sweep パラメータに渡します。オプションで、W&B Run の出力を保存したい Project の名前を Project パラメータ (project) に指定することができます。Project が指定されていない場合は、run は「Uncategorized」Project に置かれます。
import wandb
# スイープ設定の例
sweep_configuration = {
"method" : "random" ,
"name" : "sweep" ,
"metric" : {"goal" : "maximize" , "name" : "val_acc" },
"parameters" : {
"batch_size" : {"values" : [16 , 32 , 64 ]},
"epochs" : {"values" : [5 , 10 , 15 ]},
"lr" : {"max" : 0.1 , "min" : 0.0001 },
},
}
sweep_id = wandb. sweep(sweep= sweep_configuration, project= "project-name" )
wandb.sweep
W&B CLI を使用してスイープを初期化します。設定ファイルの名前を指定します。オプションで、project フラグに Project の名前を指定することができます。Project が指定されていない場合、W&B Run は「Uncategorized」Project に配置されます。
wandb sweepsweeps_demo Project のスイープを初期化し、config.yaml ファイルを設定に使用しています。
wandb sweep --project sweeps_demo config.yaml
このコマンドはスイープ ID を出力します。スイープ ID には entity 名と Project 名が含まれます。スイープ ID をメモしておいてください。
5 - sweep エージェントを開始または停止する
1 台または複数のマシン上で W&B Sweep Agent を開始または停止します。
W&B Sweep を 1 台以上のマシン上の 1 台以上のエージェントで開始します。W&B Sweep エージェントは、ハイパーパラメーターを取得するために W&B Sweep を初期化したときにローンンチされた W&B サーバーにクエリを送り、それらを使用してモデル トレーニングを実行します。
W&B Sweep エージェントを開始するには、W&B Sweep を初期化したときに返された W&B Sweep ID を指定します。W&B Sweep ID の形式は次のとおりです。
ここで:
entity: W&B のユーザー名またはチーム名。
project: W&B Run の出力を保存したいプロジェクトの名前。プロジェクトが指定されていない場合、run は「未分類」プロジェクトに置かれます。
sweep_ID: W&B によって生成される疑似ランダムな一意の ID。
Jupyter ノートブックまたは Python スクリプト内で W&B Sweep エージェントを開始する場合、W&B Sweep が実行する関数の名前を指定します。
次のコードスニペットは、W&B でエージェントを開始する方法を示しています。ここでは、既に設定ファイルを持っており、W&B Sweep を初期化済みであると仮定しています。設定ファイルを定義する方法について詳しくは、Define sweep configuration を参照してください。
CLI
Python script or notebook
sweep agent コマンドを使用してスイープを開始します。スイープを初期化するときに返されたスイープ ID を指定します。以下のコードスニペットをコピーして貼り付け、sweep_id をスイープ ID に置き換えてください:
W&B Python SDK ライブラリを使用してスイープを開始します。スイープを初期化するときに返されたスイープ ID を指定します。さらに、スイープが実行する関数の名前も指定します。
wandb. agent(sweep_id= sweep_id, function= function_name)
W&B エージェントを停止
ランダムおよびベイズ探索は永遠に実行されます。プロセスをコマンドライン、Python スクリプト内、または
Sweeps UI から停止する必要があります。
オプションで、Sweep agent が試みるべき W&B Runs の数を指定します。以下のコードスニペットは、Jupyter ノートブック、Python スクリプト内で最大の W&B Runs 数を設定する方法を示しています。
Python script or notebook
CLI
まず、スイープを初期化します。詳細は Initialize sweeps を参照してください。
sweep_id = wandb.sweep(sweep_config)
次にスイープジョブを開始します。スイープ初期化から生成されたスイープ ID を提供します。試行する run の最大数を設定するために count パラメータに整数値を渡します。
sweep_id, count = "dtzl1o7u" , 10
wandb. agent(sweep_id, count= count)
スイープエージェントが終了した後に新しい run を同じスクリプトまたはノートブック内で開始する場合は、新しい run を開始する前に wandb.teardown() を呼び出す必要があります。
まず、wandb sweepInitialize sweeps を参照してください。
wandb sweep config.yaml
試行する run の最大数を設定するために、count フラグに整数値を渡します。
NUM= 10
SWEEPID= "dtzl1o7u"
wandb agent -- count $ NUM $ SWEEPID
6 - エージェントの並列化
マルチコアまたはマルチGPUマシンでW&B sweep agentを並列化します。
W&B スイープエージェントをマルチコアまたはマルチ GPU マシンで並列化しましょう。始める前に、W&B スイープが初期化されていることを確認してください。W&B スイープの初期化方法についての詳細は、Initialize sweeps をご覧ください。
マルチ CPU マシンで並列化
ユースケースに応じて、以下のタブを参照し、CLI や Jupyter ノートブック内で W&B スイープエージェントを並列化する方法を学びましょう。
wandb agentsweep を初期化したとき に返されたスイープ ID を提供してください。
ローカルマシンで複数のターミナルウィンドウを開きます。
以下のコードスニペットをコピーして貼り付け、sweep_id をあなたのスイープ ID に置き換えます:
W&B Python SDK ライブラリを使用して、Jupyter ノートブック内で W&B スイープエージェントを複数の CPU に渡って並列化します。sweep を初期化したとき に返されたスイープ ID を確認してください。さらに、スイープが実行する関数の名前を function パラメータに提供します。
複数の Jupyter ノートブックを開きます。
複数の Jupyter ノートブックに W&B スイープ ID をコピーして貼り付け、W&B スイープを並列化します。例えば、sweep_id という変数にスイープ ID が保存されていて、関数の名前が function_name である場合、以下のコードスニペットを複数の Jupyter ノートブックに貼り付けることができます:
wandb. agent(sweep_id= sweep_id, function= function_name)
マルチ GPU マシンで並列化
CUDA Toolkit を使用して、ターミナルで W&B スイープエージェントを複数の GPU に渡って並列化するための手順に従ってください。
ローカルマシンで複数のターミナルウィンドウを開きます。
W&B スイープジョブを開始するときに CUDA_VISIBLE_DEVICES を使用して使用する GPU インスタンスを指定します(wandb agentCUDA_VISIBLE_DEVICES に使用する GPU インスタンスに対応する整数値を割り当てます。
例えば、ローカルマシンに 2 つの NVIDIA GPU があると仮定します。ターミナルウィンドウを開き、CUDA_VISIBLE_DEVICES を 0(CUDA_VISIBLE_DEVICES=0)に設定します。以下の例で、sweep_ID を初期化したときに返された W&B スイープ ID に置き換えます:
ターミナル 1
CUDA_VISIBLE_DEVICES= 0 wandb agent sweep_ID
2 番目のターミナルウィンドウを開きます。CUDA_VISIBLE_DEVICES を 1(CUDA_VISIBLE_DEVICES=1)に設定します。次のコードスニペットで言及された sweep_ID に同じ W&B スイープ ID を貼り付けます:
ターミナル 2
CUDA_VISIBLE_DEVICES= 1 wandb agent sweep_ID
7 - sweep 結果を可視化する
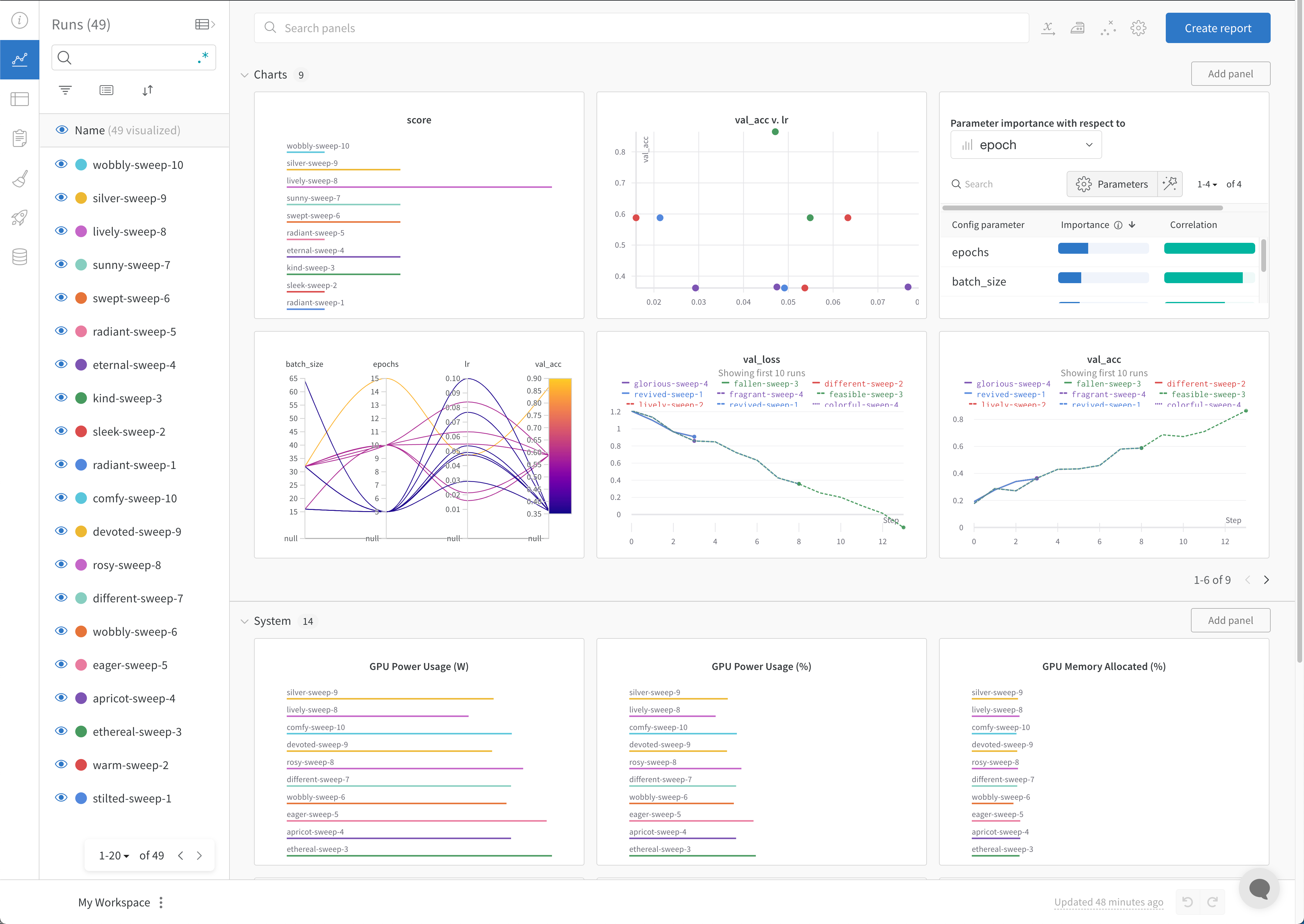
W&B App UI で W&B スイープの結果を可視化します。
Visualize の結果を W&B Sweeps の W&B App UI で確認しましょう。https://wandb.ai/home にアクセスして、W&B App UI に移動します。W&B Sweep を初期化した際に指定したプロジェクトを選択します。プロジェクトのworkspace にリダイレクトされます。左側のパネルから Sweep アイコン (ほうきのアイコン)を選択します。 Sweep UI で、リストから Sweep の名前を選択します。
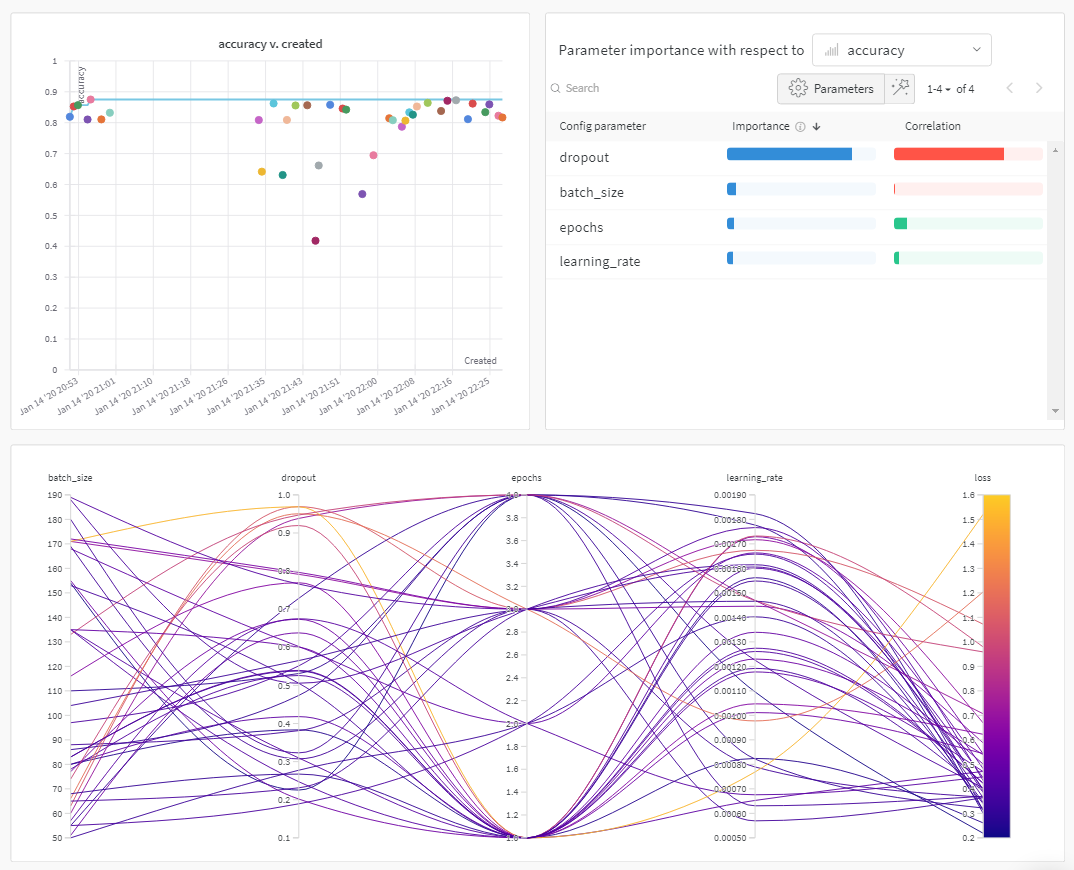
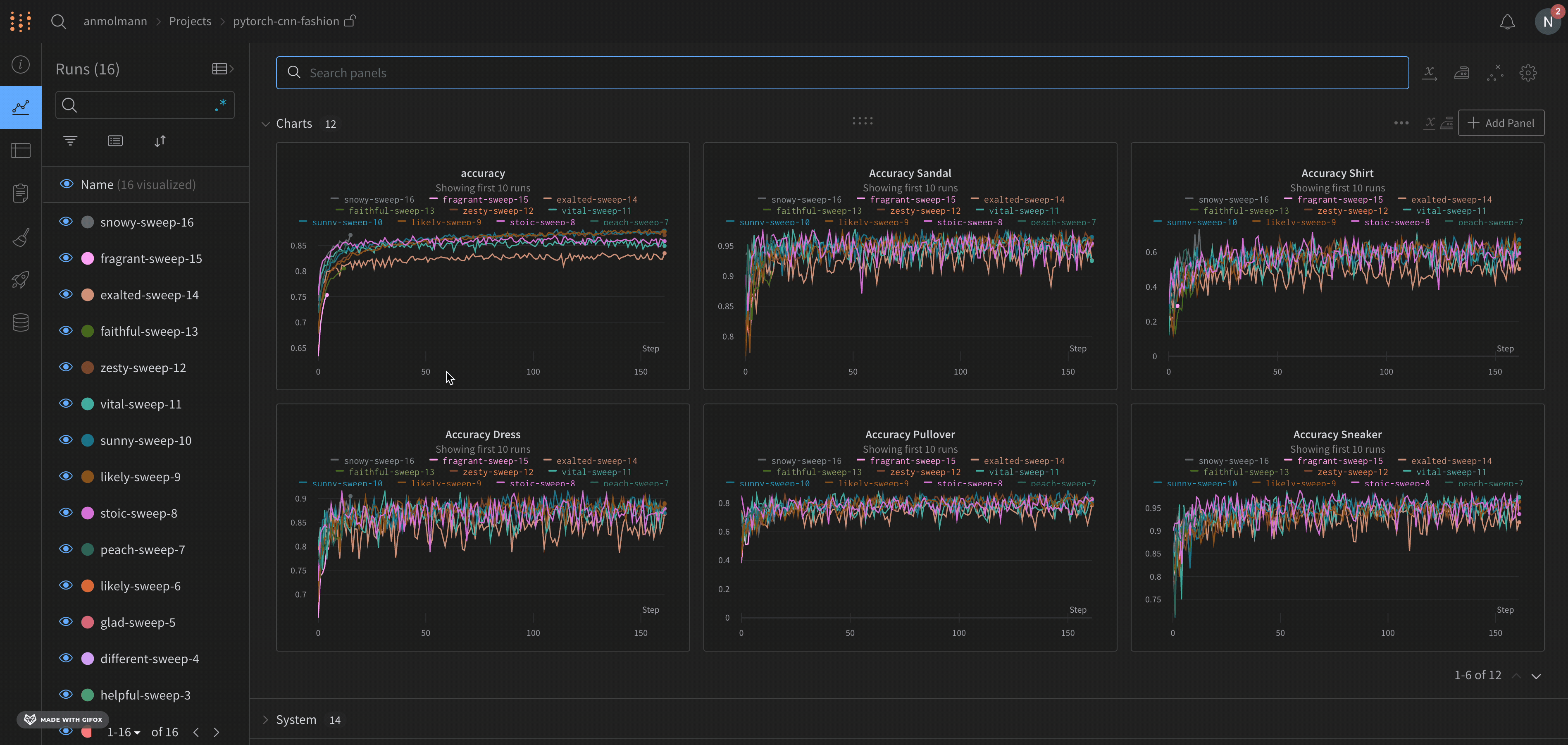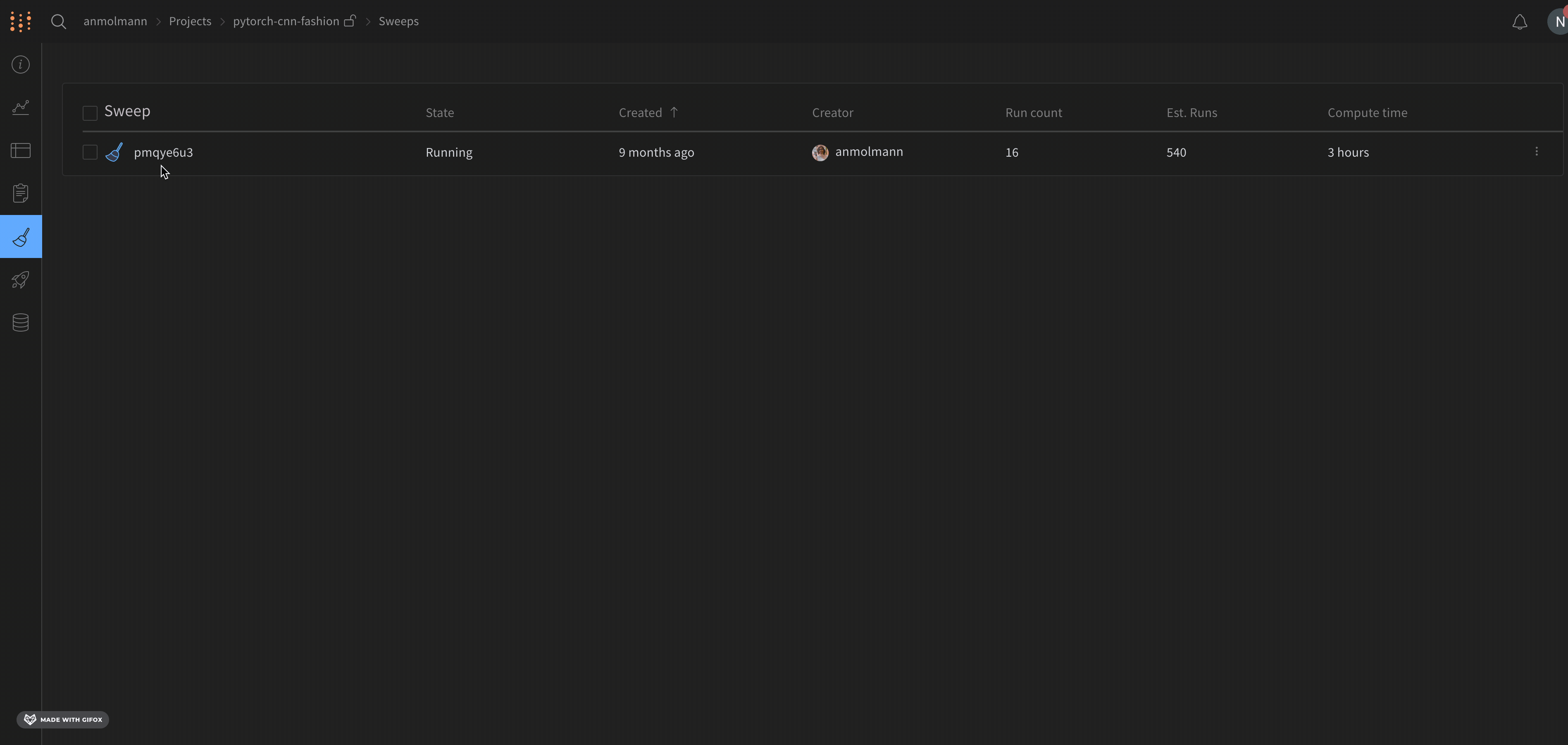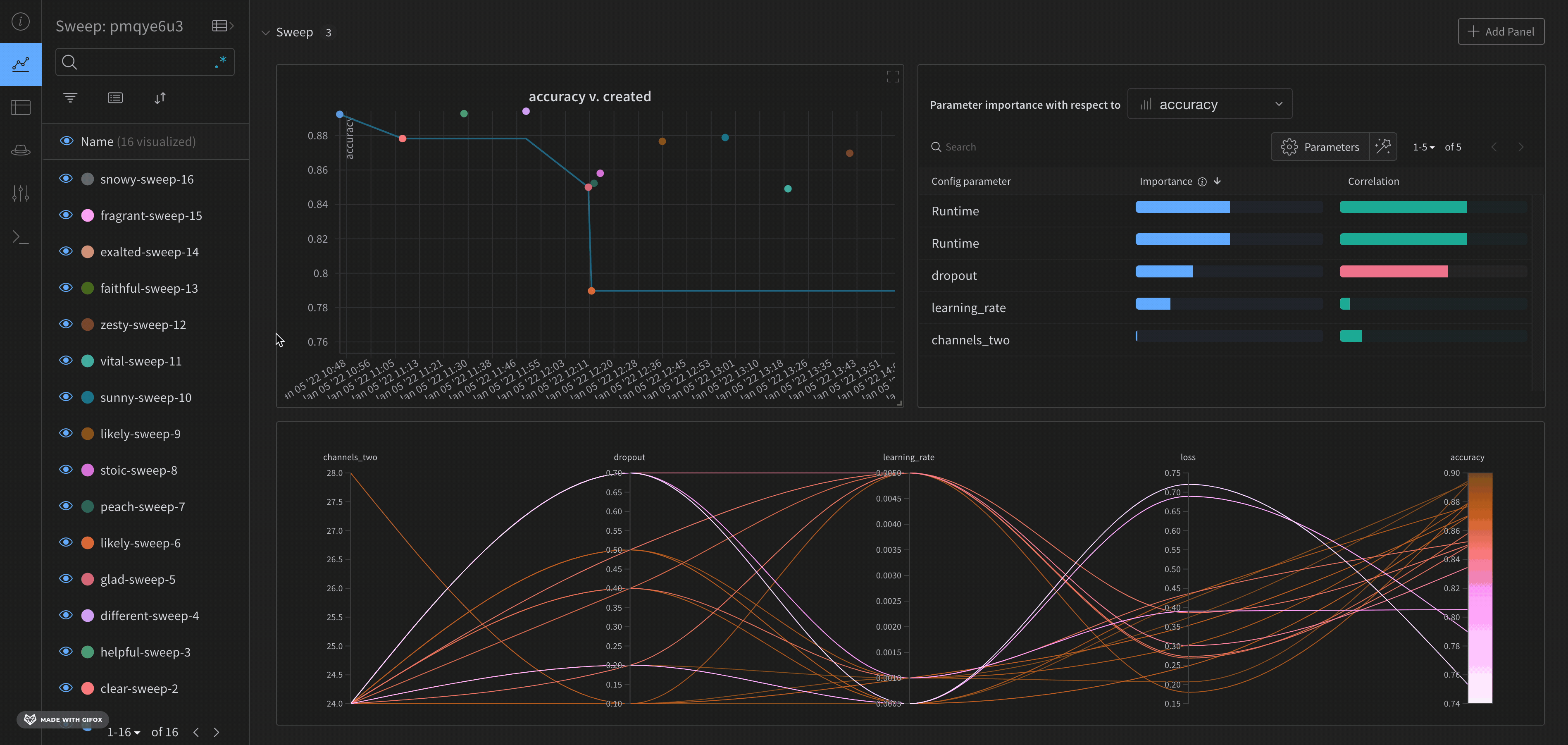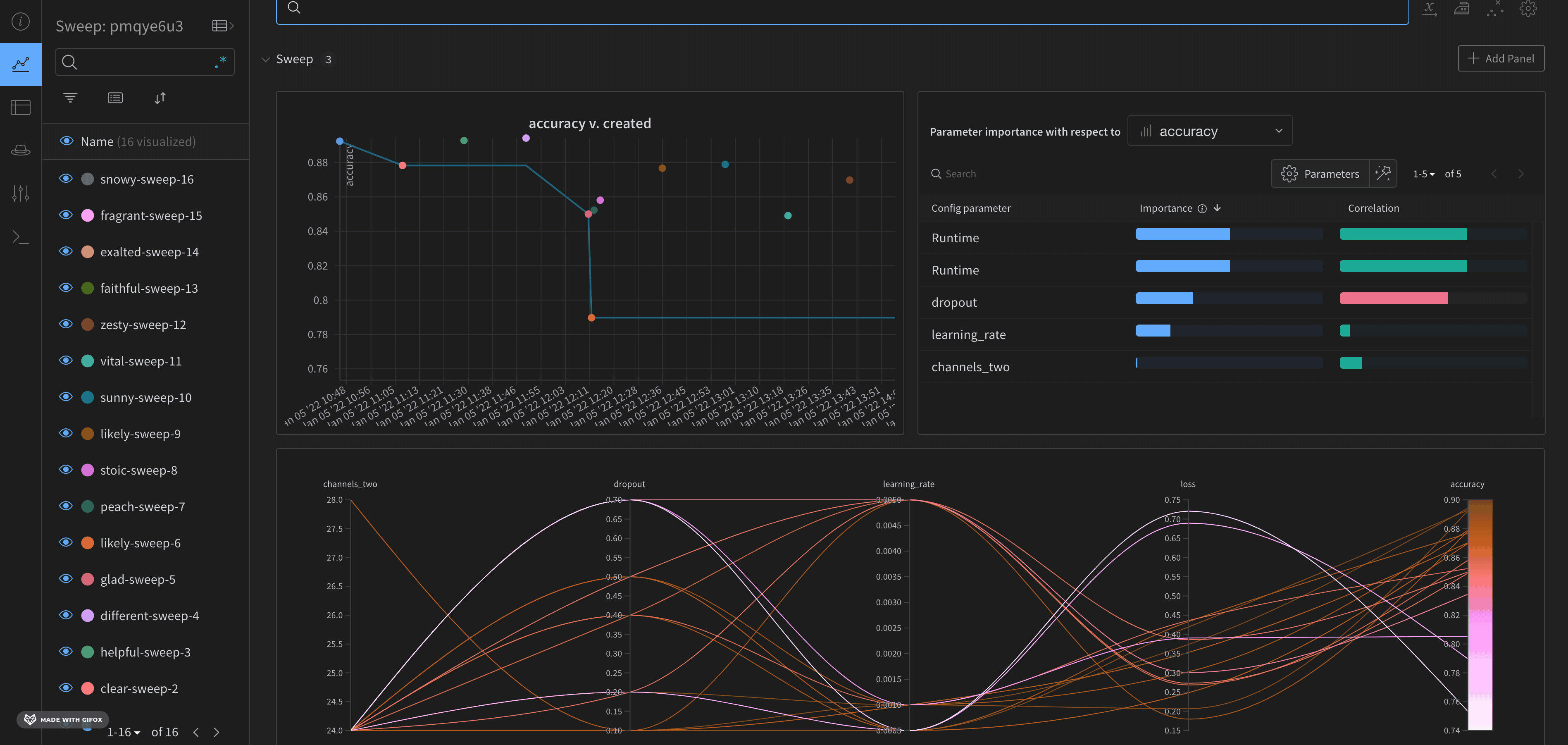
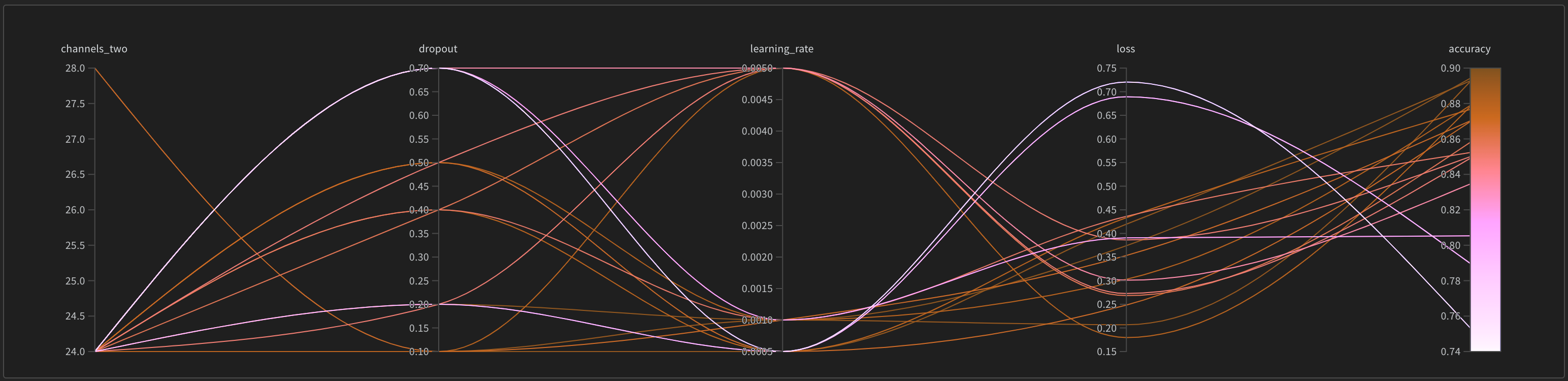
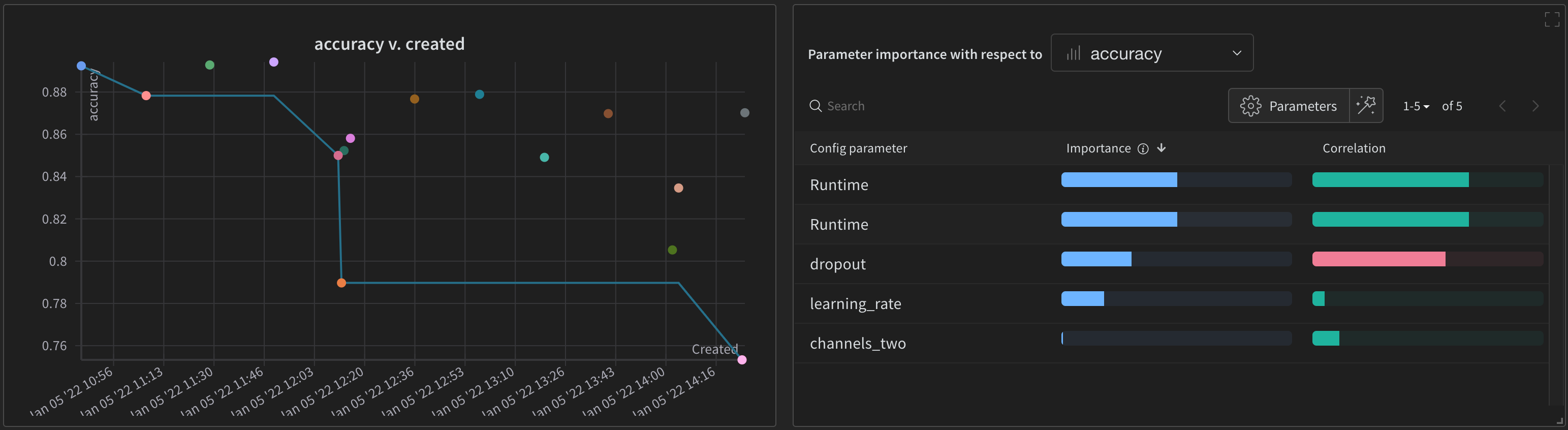
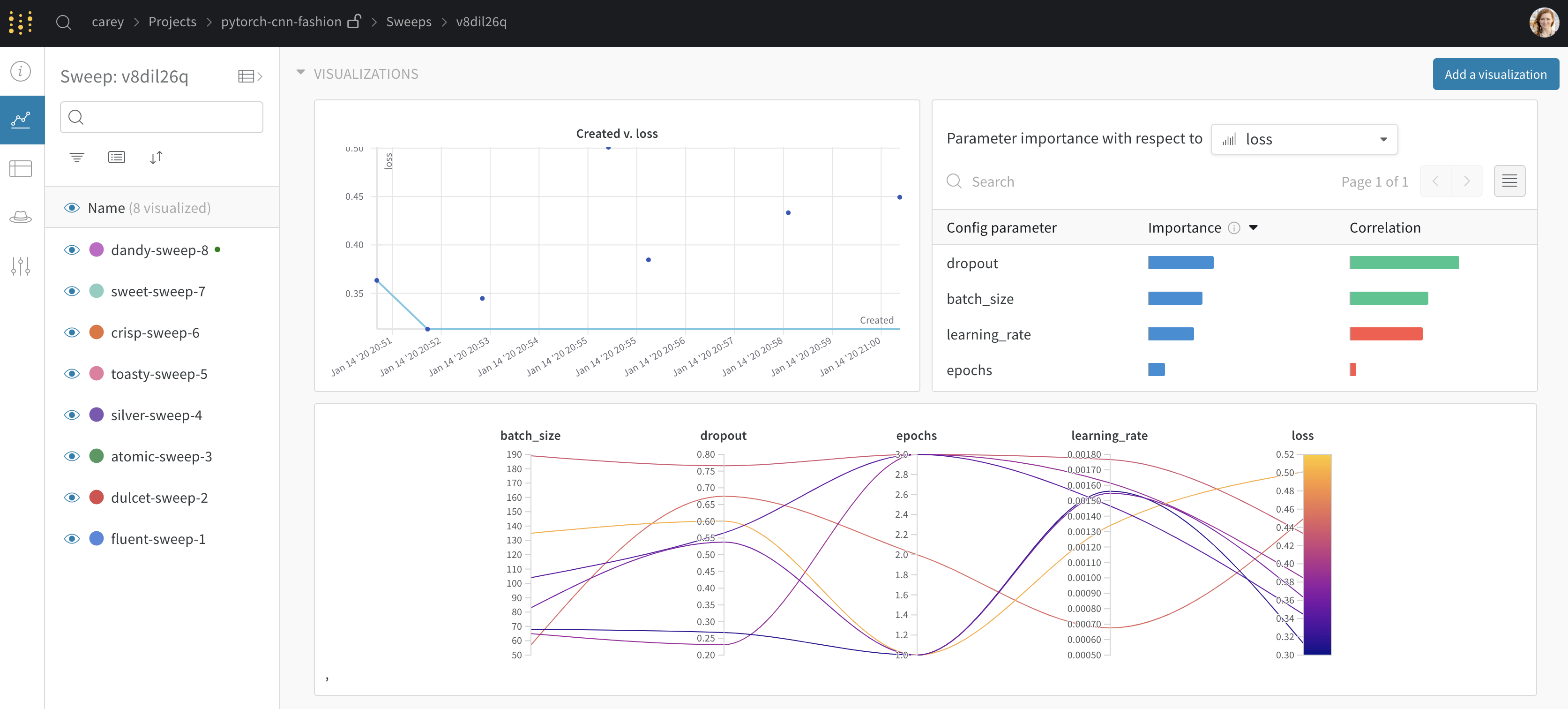
デフォルトでは、W&B は W&B Sweep ジョブを開始すると、パラレル座標プロット、パラメータの重要度プロット、そして散布図を自動的に作成します。
パラレル座標チャートは、多数のハイパーパラメーターとモデルメトリクスの関係を一目で要約します。パラレル座標プロットの詳細については、パラレル座標 を参照してください。
左の散布図は、Sweep の間に生成された W&B Runs を比較します。散布図の詳細については、散布図 を参照してください。
右のパラメータの重要度プロットは、メトリクスの望ましい値と高度に相関するハイパーパラメーターをリストアップします。パラメータの重要度プロットの詳細については、パラメータの重要度 を参照してください。
自動で使用される従属と独立の値(x と y 軸)を変更できます。各パネル内には Edit panel という鉛筆のアイコンがあります。Edit panel を選択します。モデルが表示されます。そのモデル内で、グラフの振る舞いを変更することができます。
すべてのデフォルトの W&B 可視化オプションの詳細については、パネル を参照してください。W&B Sweep の一部ではない W&B Runs からプロットを作成する方法については、Data Visualization docs を参照してください。
8 - スイープを CLI で管理する
W&B Sweep を CLI で一時停止、再開、キャンセルします。
W&B Sweep を CLI で一時停止、再開、キャンセルすることができます。W&B Sweep を一時停止すると、新しい W&B Runs を再開するまで実行しないよう W&B エージェントに指示します。Sweep を再開すると、エージェントに新しい W&B Run の実行を続けるよう指示します。W&B Sweep を停止すると、W&B Sweep エージェントに新しい W&B Run の作成や実行を停止するように指示します。W&B Sweep をキャンセルすると、現在実行中の W&B Run を強制終了し、新しい Runs の実行を停止するよう Sweep エージェントに指示します。
それぞれの場合に、W&B Sweep を初期化したときに生成された W&B Sweep ID を指定します。新しいターミナルウィンドウを開いて、以下のコマンドを実行します。新しいターミナルウィンドウを開くと、現在のターミナルウィンドウに W&B Sweep が出力ステートメントを表示している場合でも、コマンドをより簡単に実行できます。
スイープを一時停止、再開、およびキャンセルするための次のガイダンスを使用してください。
スイープを一時停止する
W&B Sweep を一時的に停止して新しい W&B Run の実行を一時停止します。wandb sweep --pause コマンドを使用して W&B Sweep を一時停止します。一時停止したい W&B Sweep ID を指定します。
wandb sweep --pause entity/project/sweep_ID
スイープを再開する
一時停止している W&B Sweep を wandb sweep --resume コマンドで再開します。再開したい W&B Sweep ID を指定します。
wandb sweep --resume entity/project/sweep_ID
スイープを停止する
W&B スイープを完了し、新しい W&B Runs の実行を停止し、現在実行中の Runs が終了するのを待ちます。
wandb sweep --stop entity/project/sweep_ID
スイープをキャンセルする
すべての実行中の run を強制終了し、新しい run の実行を停止するためにスイープをキャンセルします。wandb sweep --cancel コマンドを使用して W&B Sweep をキャンセルします。キャンセルしたい W&B Sweep ID を指定します。
wandb sweep --cancel entity/project/sweep_ID
CLI コマンドオプションの全リストについては、wandb sweep CLI リファレンスガイドを参照してください。
複数のエージェントにわたってスイープを一時停止、再開、停止、キャンセルする
単一のターミナルから複数のエージェントにわたって W&B Sweep を一時停止、再開、停止、またはキャンセルします。たとえば、マルチコアマシンを持っていると仮定します。W&B Sweep を初期化した後、ターミナルウィンドウを新たに開き、各新しいターミナルに Sweep ID をコピーします。
任意のターミナル内で、wandb sweep CLI コマンドを使用して W&B Sweep を一時停止、再開、停止、またはキャンセルします。たとえば、以下のコードスニペットは、CLI を使用して複数のエージェントにわたって W&B Sweep を一時停止する方法を示しています。
wandb sweep --pause entity/project/sweep_ID
--resume フラグと共に Sweep ID を指定して、エージェントにわたって Sweep を再開します。
wandb sweep --resume entity/project/sweep_ID
W&B エージェントを並列化する方法の詳細については、Parallelize agents を参照してください。
9 - アルゴリズムをローカルで管理する
W&B のクラウドホスティッドサービスを使用せずに、ローカルで検索およびストップアルゴリズムを実行します。
ハイパーパラメータコントローラは、デフォルトでウェイト&バイアスによってクラウドサービスとしてホストされています。W&Bエージェントはコントローラと通信して、トレーニングに使用する次のパラメータセットを決定します。コントローラは、どのrunを停止するかを決定するための早期停止アルゴリズムの実行も担当しています。
ローカルコントローラ機能により、ユーザーはアルゴリズムをローカルで検索および停止することができます。ローカルコントローラは、ユーザーにコードを検査および操作する能力を与え、問題のデバッグやクラウドサービスに組み込むことができる新機能の開発を可能にします。
この機能は、Sweepsツールの新しいアルゴリズムの迅速な開発とデバッグをサポートするために提供されています。本来のハイパーパラメータ最適化のワークロードを目的としていません。
始める前に、W&B SDK (wandb) をインストールする必要があります。次のコマンドをコマンドラインに入力してください:
pip install wandb sweeps
以下の例では、既に設定ファイルとPythonスクリプトまたはJupyterノートブックで定義されたトレーニングループがあることを前提としています。設定ファイルの定義方法についての詳細は、Define sweep configuration を参照してください。
コマンドラインからローカルコントローラを実行する
通常、W&Bがホストするクラウドサービスのハイパーパラメータコントローラを使用する際と同様に、スイープを初期化します。ローカルコントローラをW&Bスイープジョブ用に使用することを示すために、コントローラフラグ (controller) を指定します:
wandb sweep --controller config.yaml
または、スイープを初期化することと、ローカルコントローラを使用することを指定することを2つのステップに分けることもできます。
ステップを分けるには、まず次のキーと値をスイープのYAML設定ファイルに追加します:
次に、スイープを初期化します:
スイープを初期化した後、wandb controller
# wandb sweep コマンドが sweep_id を出力します
wandb controller { user} /{ entity} /{ sweep_id}
ローカルコントローラを使用することを指定した後、スイープを実行するために1つ以上のSweepエージェントを開始します。通常のW&Bスイープを開始するのと同じようにしてください。Start sweep agents を参照してください。
W&B Python SDKを使用してローカルコントローラを実行する
以下のコードスニペットは、W&B Python SDKを使用してローカルコントローラを指定し、使用する方法を示しています。
Python SDKでコントローラを使用する最も簡単な方法は、wandb.controllerrun メソッドを使用してスイープジョブを開始します:
sweep = wandb. controller(sweep_id)
sweep. run()
コントローラループをより詳細に制御したい場合:
import wandb
sweep = wandb. controller(sweep_id)
while not sweep. done():
sweep. print_status()
sweep. step()
time. sleep(5 )
パラメータの提供に関してさらに詳細なコントロールが必要な場合:
import wandb
sweep = wandb. controller(sweep_id)
while not sweep. done():
params = sweep. search()
sweep. schedule(params)
sweep. print_status()
コードですべてのスイープを指定したい場合は、次のように実装できます:
import wandb
sweep = wandb. controller()
sweep. configure_search("grid" )
sweep. configure_program("train-dummy.py" )
sweep. configure_controller(type= "local" )
sweep. configure_parameter("param1" , value= 3 )
sweep. create()
sweep. run()
10 - スイープ UI
スイープ UI のさまざまなコンポーネントを説明します。
状態 (State )、作成時間 (Created )、スイープを開始したエンティティ (Creator )、完了した run の数 (Run count )、スイープの計算にかかった時間 (Compute time ) が Sweeps UI に表示されます。スイープが作成する予想 run の数 (Est. Runs ) は、離散探索空間でグリッド検索を行うと提供されます。インターフェースからスイープをクリックして、一時停止、再開、停止、または終了させることもできます。
11 - スイープについて詳しく学ぶ
役立つSweepsの情報源のコレクション。
Academic papers
Li, Lisha, et al. “Hyperband: A novel bandit-based approach to hyperparameter optimization. ” The Journal of Machine Learning Research 18.1 (2017): 6765-6816.
Sweep Experiments
次の W&B Reports では、W&B Sweeps を使用したハイパーパラメータ最適化を探るプロジェクトの例を紹介しています。
selfm-anaged
次のハウツーガイドでは、W&B を使用して現実世界の問題を解決する方法を示しています:
Sweep GitHub repository
W&B はオープンソースを推奨し、コミュニティからの貢献を歓迎します。GitHub リポジトリは https://github.com/wandb/sweeps で見つけることができます。W&B オープンソース リポジトリへの貢献方法については、W&B GitHub Contribution guidelines を参照してください。
12 - スイープのトラブルシューティング
一般的な W&B Sweep の問題をトラブルシュートする。
一般的なエラーメッセージのトラブルシューティングには、提案されたガイダンスを参照してください。
CommError, Run does not exist および ERROR Error uploadingこれら2つのエラーメッセージが返される場合、W&B Run ID が定義されている可能性があります。例えば、Jupyter Notebooks や Python スクリプトのどこかに類似のコードスニペットが定義されているかもしれません。
wandb. init(id= "some-string" )
W&B Sweeps では Run ID を設定することはできません。なぜなら、W&B が作成する Runs には、W&B が自動的にランダムで一意の ID を生成するからです。
W&B Run IDs は、プロジェクト内で一意である必要があります。
テーブルやグラフに表示するカスタム名を設定したい場合は、W&B を初期化するときに name パラメータに名前を渡すことをお勧めします。例えば:
wandb. init(name= "a helpful readable run name" )
Cuda out of memoryこのエラーメッセージが表示される場合は、プロセスベースの実行を使用するようにコードをリファクタリングしてください。具体的には、コードを Python スクリプトに書き換えてください。また、W&B Python SDK ではなく CLI から W&B Sweep Agent を呼び出してください。
例として、コードを train.py という名の Python スクリプトに書き直すとします。その際、トレーニングスクリプト (train.py) の名前を YAML Sweep 設定ファイル (config.yaml の例) に追加します。
program : train.py
method : bayes
metric :
name : validation_loss
goal : maximize
parameters :
learning_rate :
min : 0.0001
max : 0.1
optimizer :
values : ["adam" , "sgd" ]
次に、Python スクリプト train.py に以下を追加します。
if _name_ == "_main_" :
train()
CLI に移動して、wandb sweep を使用して W&B Sweep を初期化します。
返された W&B Sweep ID をメモします。次に、 Sweep のジョブを CLI で wandb agentwandb.agentsweep_ID を前のステップで返された Sweep ID に置き換えてください。
anaconda 400 errorこのエラーは通常、最適化しているメトリックをログしていない場合に発生します。
wandb: ERROR Error while calling W&B API: anaconda 400 error:
{ "code" : 400, "message" : "TypeError: bad operand type for unary -: 'NoneType'" }
YAML ファイルやネストされた辞書内で、最適化する「metric」 というキーを指定します。このメトリックをログ (wandb.log) することを確認してください。また、Python スクリプトや Jupyter Notebook 内で最適化するように定義した exact なメトリック名を必ず使用してください。設定ファイルについての詳細は、Define sweep configuration を参照してください。
13 - チュートリアル: プロジェクトから sweep ジョブを作成する
既存の W&B プロジェクトから sweep ジョブを作成する方法に関するチュートリアル。
このチュートリアルでは、既存の W&B プロジェクトからスイープジョブを作成する方法を説明します。PyTorch の畳み込みニューラルネットワークを用いて画像を分類するために Fashion MNIST dataset を使用します。必要なコードとデータセットは、W&B のリポジトリにあります:https://github.com/wandb/examples/tree/master/examples/pytorch/pytorch-cnn-fashion
この W&B ダッシュボード で結果を探索してください。
1. プロジェクトを作成する
最初にベースラインを作成します。W&B の GitHub リポジトリから PyTorch MNIST データセットの例モデルをダウンロードします。次に、モデルをトレーニングします。そのトレーニングスクリプトは examples/pytorch/pytorch-cnn-fashion ディレクトリーにあります。
このリポジトリをクローンします git clone https://github.com/wandb/examples.git
この例を開きます cd examples/pytorch/pytorch-cnn-fashion
run を手動で実行します python train.py
オプションとして、W&B アプリ UI ダッシュボードで例を探索します。
例のプロジェクトページを見る →
2. スイープを作成する
あなたのプロジェクトページから、サイドバーの Sweep tab を開き、Create Sweep を選択します。
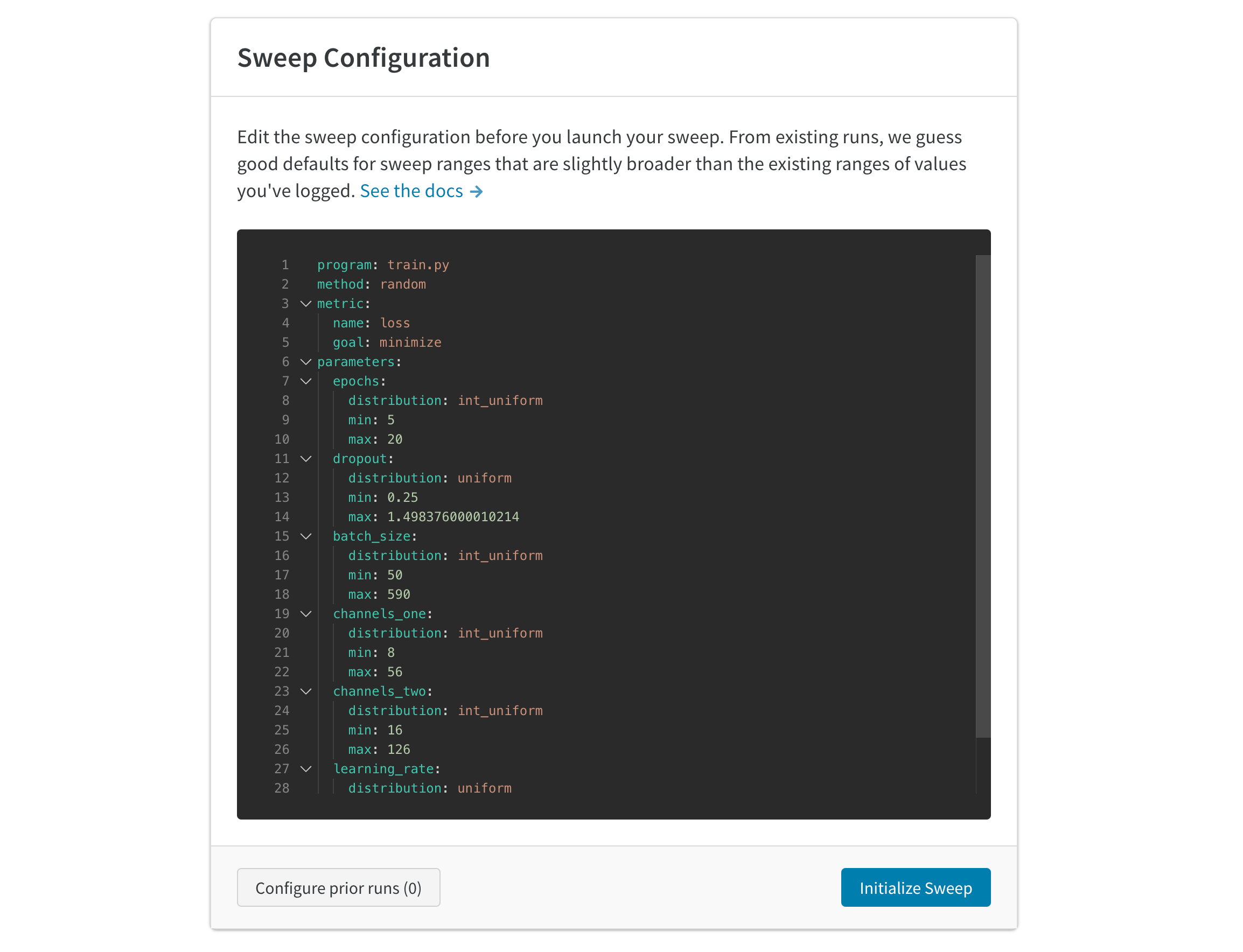
自動生成された設定は、完了した run に基づいてスイープする値を推測します。試したいハイパーパラメーターの範囲を指定するために設定を編集します。スイープをローンチすると、ホストされた W&B スイープサーバー上で新しいプロセスが開始されます。この集中サービスは、トレーニングジョブを実行しているエージェント(機械)を調整します。
3. エージェントをローンチする
次に、ローカルでエージェントをローンチします。作業を分散してスイープジョブをより早く終わらせたい場合は、最大20のエージェントを異なるマシンで並行してローンチすることができます。エージェントは、次に試すパラメータのセットを出力します。
これで、スイープを実行しています。以下の画像は、例のスイープジョブが実行されているときのダッシュボードがどのように見えるかを示しています。例のプロジェクトページを見る →
既存の run で新しいスイープをシードする
以前にログした既存の run を使用して新しいスイープをローンチします。
プロジェクトテーブルを開きます。
表の左側のチェックボックスを使用して使用したい run を選択します。
新しいスイープを作成するためにドロップダウンをクリックします。
スイープはサーバー上に設定されます。run を開始するために、1つ以上のエージェントをローンチするだけです。
新しいスイープをベイジアンスイープとして開始すると、選択した run はガウスプロセスにもシードされます。